Ghidra 逆向 p1:工具的基本使用方法
坑边闲话:笔者使用 IDA Pro 进行程序分析已经有很多年了,来到欧洲之后发现大部分人喜欢用开源免费的 Ghidra,或许是他们比较尊重版权而不屑于使用盗版的 IDA Pro 吧。既然决定入乡,随俗便是不可避免的。经过一番学习,我终于初步学会了如何使用 Ghidra 进行逆向分析。
1. Ghidra 安装·
Ghidra 使用 Java 进行开发,因此具有极好的跨平台能力。Java 代码“一次编译,处处运行”,因此所有平台的 Ghidra 安装包是相同的。Java 的图形化界面没有原生开发那么细腻,所以 Ghidra 初看上去有些粗陋,但看习惯了也还好,毕竟它的功能强大、逻辑严密。这就好比找了个外貌没那么惊艳的女朋友,但是因为她内在修养很好,相处久了也感到舒服。
1.1 安装 JDK·
JDK 是 Java 开发库,只有安装了 JDK 才可以运行 Ghidra. macOS 和 Linux 通过包管理器安装完之后,需要在 ~/.bashrc 或 ~/.config/zsh/.zshrc 或其他 shell init 脚本里指定 ${JAVA_HOME} 环境变量为 JDK 所在目录。
JDK 目录的结构如下:
1.2 安装 Ghidra·
在官方 Github 的 Release 界面下载最新版 Ghidra,然后解压到一个合适的目录即可。这次采用的是 ~/bin/ghidra.
经过笔者配置,该目录结构大致如下:
1 | . |
Java 软件的启动一般是通过命令行进行。在 macOS 和 Linux 界面,通过双击 ghidraRun 即可打开;在 Windows 平台,通过双击 ghidraRun.bat 批处理文件打开。不得不承认,这种启动方式不优雅,每次启动完成还要手动关闭 Terminal 窗口显得多此一举。
由此就基本完成了 Ghidra 的安装。
2. Ghidra 入门·
2.1 创建工程·
Ghidra 基于 Project 工作,而 IDA Pro 基于可执行文件和 idb 数据库工作。归根结底,两者的概念是类似的,那就是将可执行文件以只读文件的形式分析,然后将分析结果以某种格式或格式组保存在一个固定的地方。我本人比较喜欢 Ghidra 基于工程的逻辑,因为 IDA Pro 在不正确关闭后,idb 数据库不能自动打包而显得很乱。
笔者习惯将工程根目录设置为 ~/Documents/Ghidra_Projects. 随后将新的工程保存在该目录下,总体上显得井然有序。
使用 File 菜单,创建一个非共享的工程,即可往工程里拖拽可执行文件、裸 bin 文件。
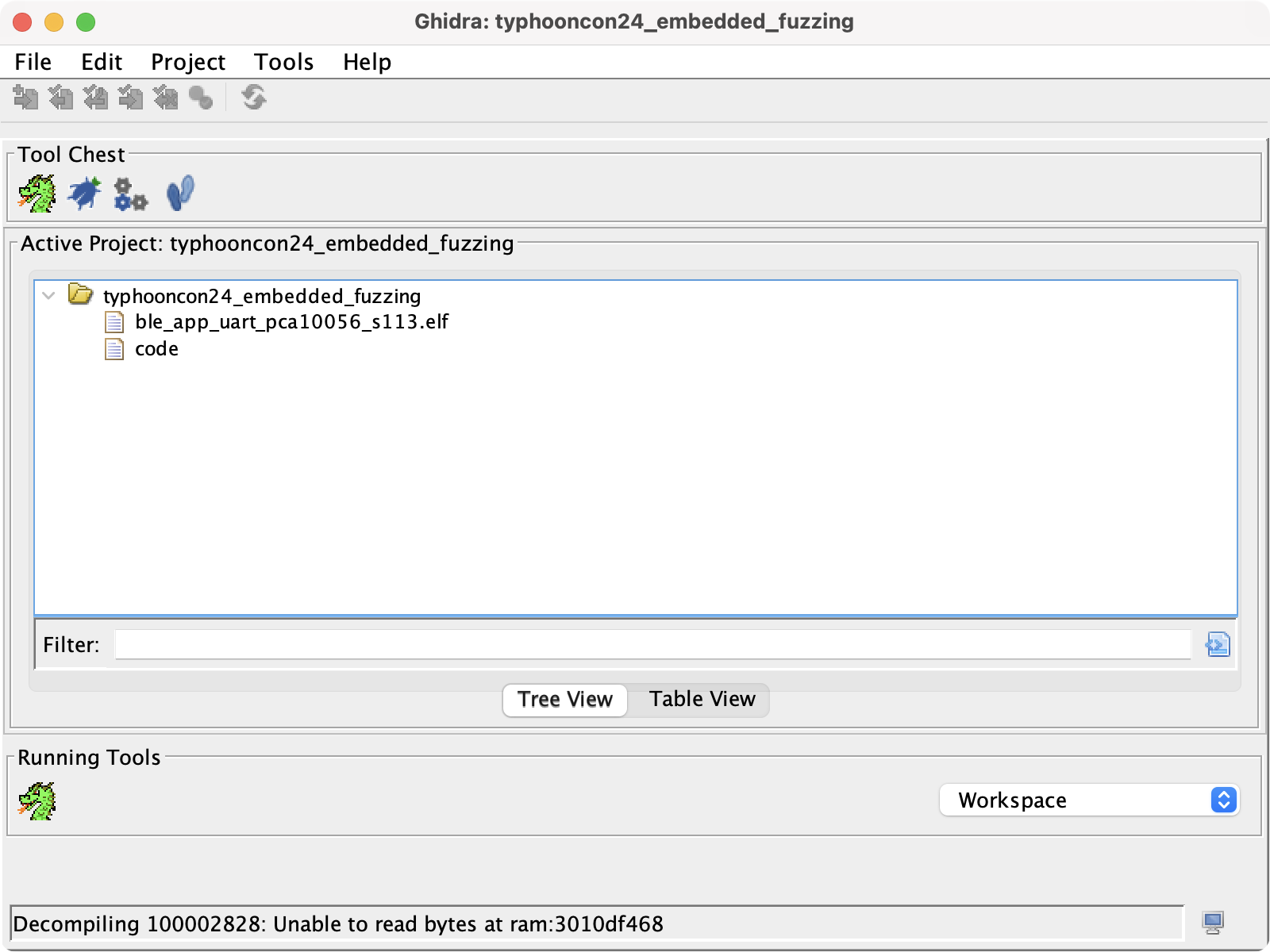
2.2 导入被分析对象·
在上一步骤中我们拖入了两个被分析的对象。不过要注意,选择合适的指令集是让 Ghidra 正确分析的必要条件。由于 ble_app_uart_pca10056_s113.elf 和 code(VSCode 的命令行启动器)均为自带描述信息的高级格式,所以 Ghidra 可以借助描述信息选择最匹配的硬件语言,如 ARMv7 和 AppleSilicon.
接下来我们拖入一个从 ROM 里 dump 出的名为 firmware.bin 的 bin 文件进行分析。
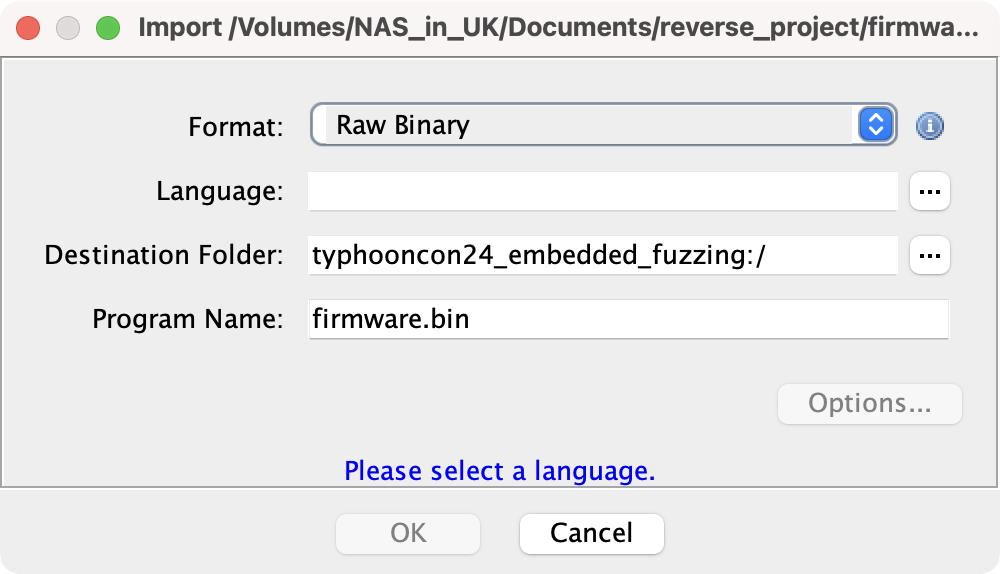
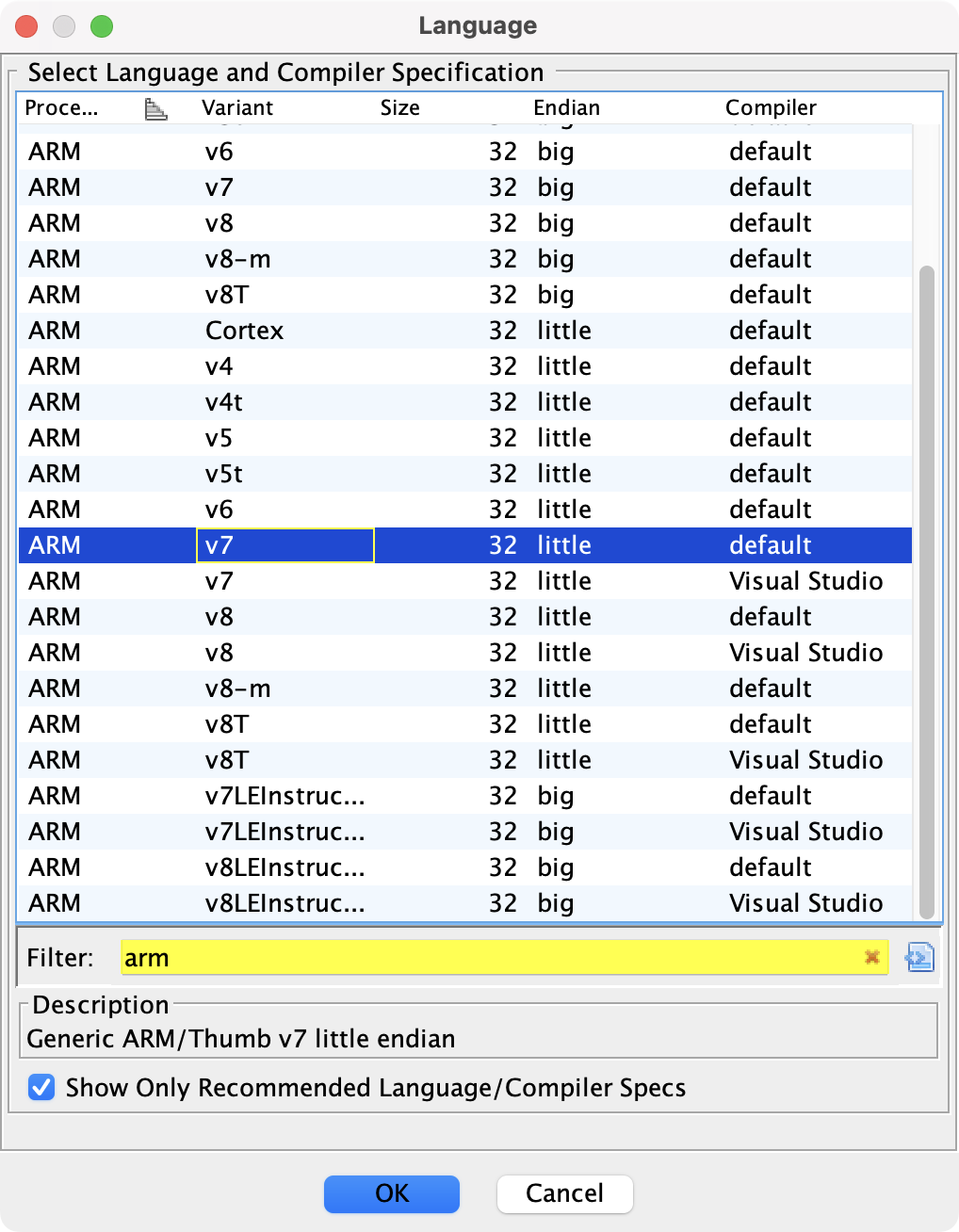
选择了错误的语言,将导致无法进行任何有效分析。
此外,在 Options 扩展菜单中,还可以设置 bin 文件块的名字(如 RAM 或 ROM,帮助后期理解)、块的其实地址等。
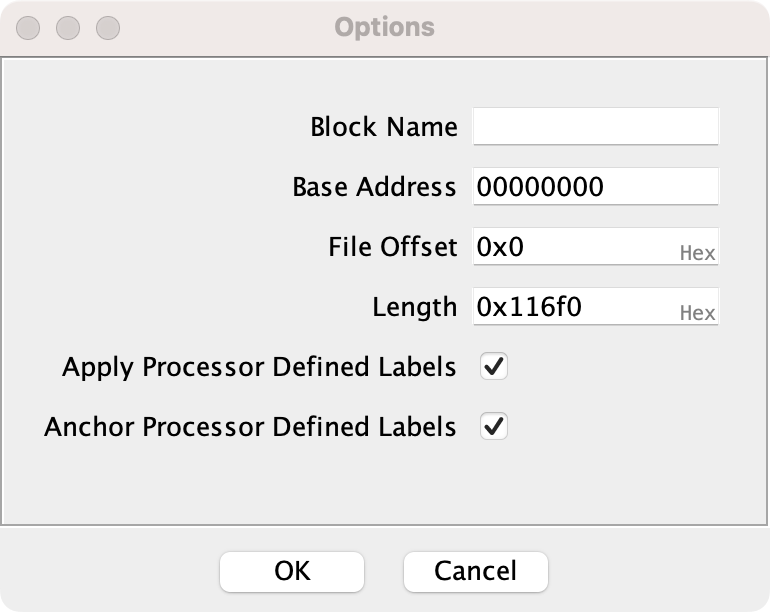
2.3 微调被分析对象·
在 Project Manager 面板,双击被分析对象即可进入 Code Browser 主界面。
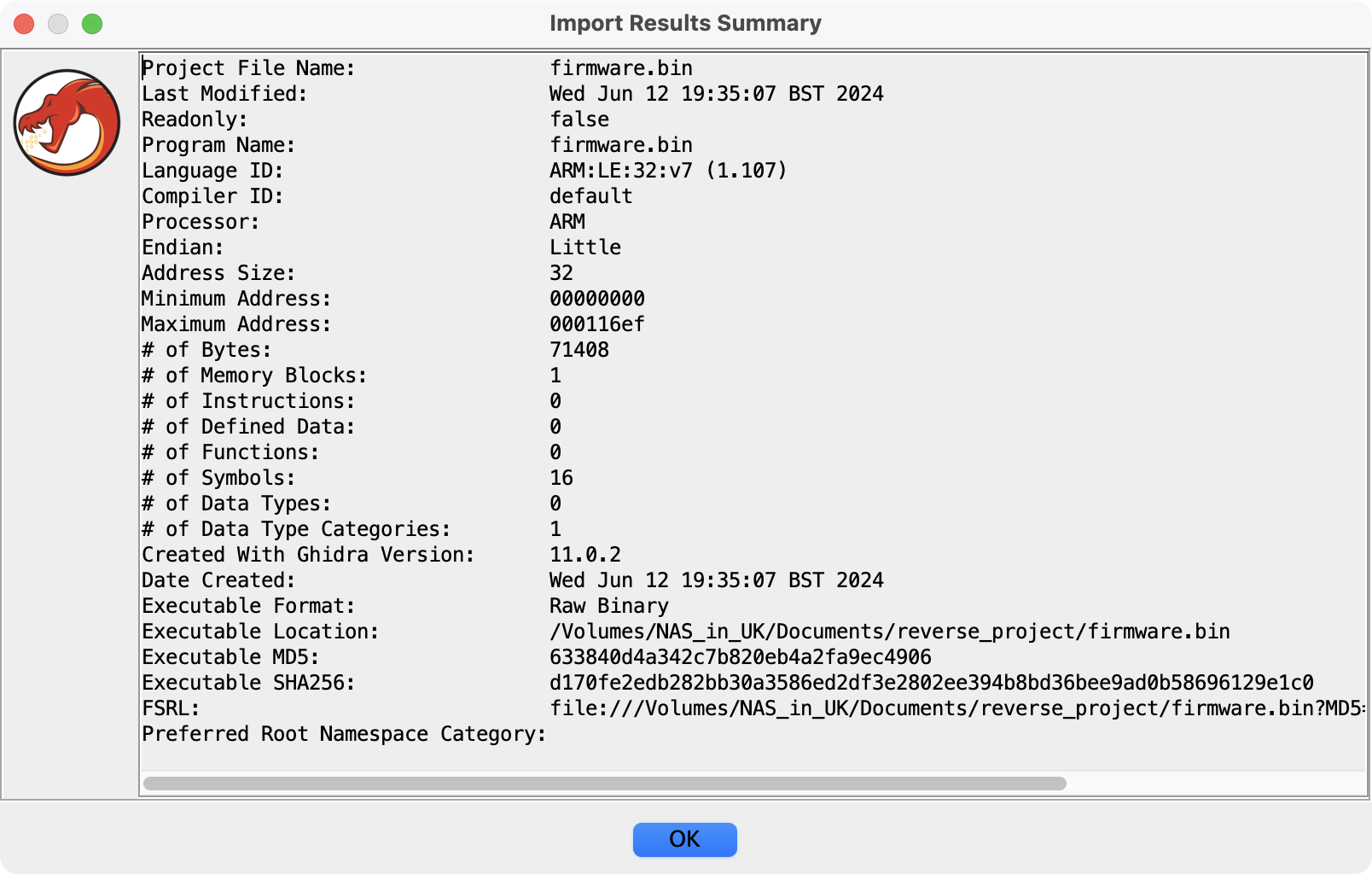
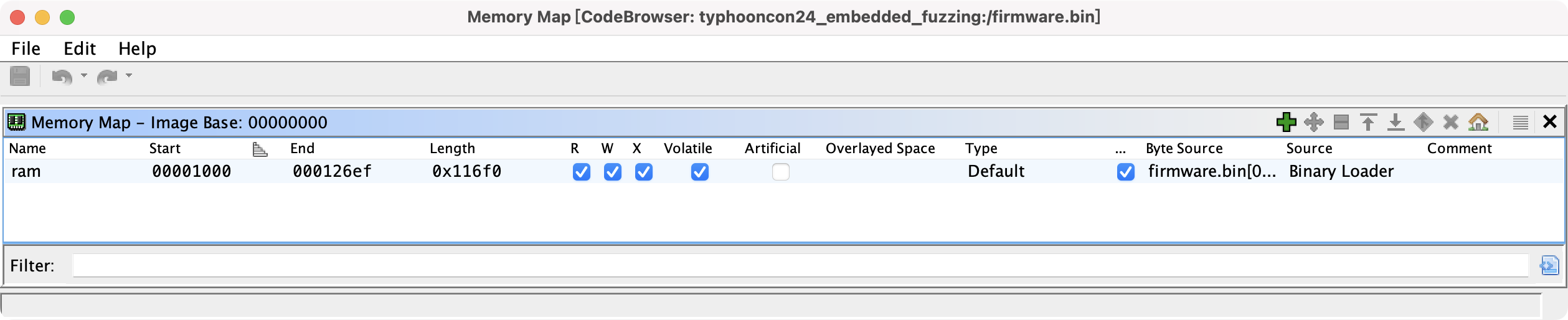
高级文件格式均可有效自解释,因此我们不做过多描述。对于从嵌入式设备的内存、ROM 中 dump 出的对象,需要设置合适的入口地址。以本文件为例,图 6 显示其实地址 Minimum Address 为 0x00000000,终点地址 Maximum Address 为 0x000116ef. 这是很不寻常的!对于错误的入口地址,根据 PC 寄存器做相对跳转时的目标地址就产生错位,无法进行分析。这类似给衬衣系扣子,第一个错了,后面的大概率就全错。
如果你需要微调,进入主界面后就不要选择自动分析。后面我们会在分析菜单对分析功能做深入介绍。
3. Code Browser 面板常见操作·
本章内容涉及一些使用频率极高的操作。
3.1 数据类型转换·
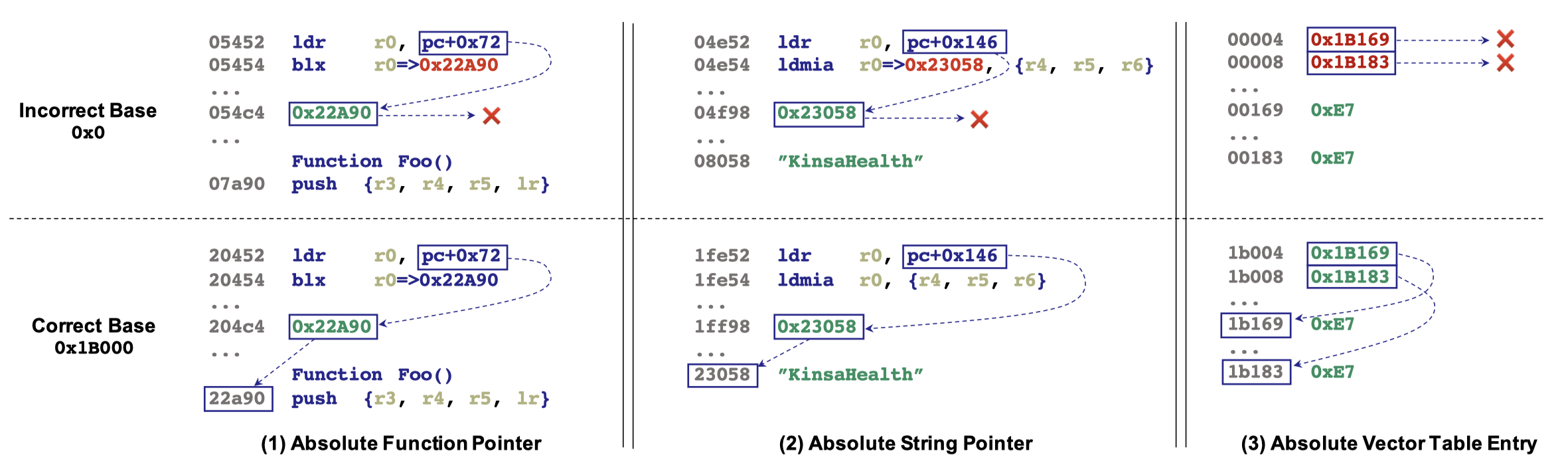
熟悉 C 语言的读者应该清楚,char 可以被解释为 int,反过来也一样。因此,被分析对象 firmware.bin 作为一个字节数组,该如何理解其中字节的含义呢?比如单个字节可能是一个字符,连续的四个字节可能是一个地址(指针),因此 Ghidra 用户要对程序的运行逻辑有相当的了解才能从迷雾中发现清晰的逻辑。
- 对于 Cortex-M3/M4,约定 ROM 的起始地址为主栈指针
MSP,因此前四个字节应该是一个指向ram段的指针; - 后续的 32 位字,应当被解释为中断向量表的表项,所以接下来每四个字节均是指向
text段的指针;
由于 Cortex-M3/M4 的向量表采取绝对地址跳转,所以段起始地址写错,所有的中断处理函数均无法识别,切记!

既然前四个字节应该被解释为指向内存段的指针,因此按下快捷键 p 将其转换为 Pointer. 格式转换也可参照右键菜单:
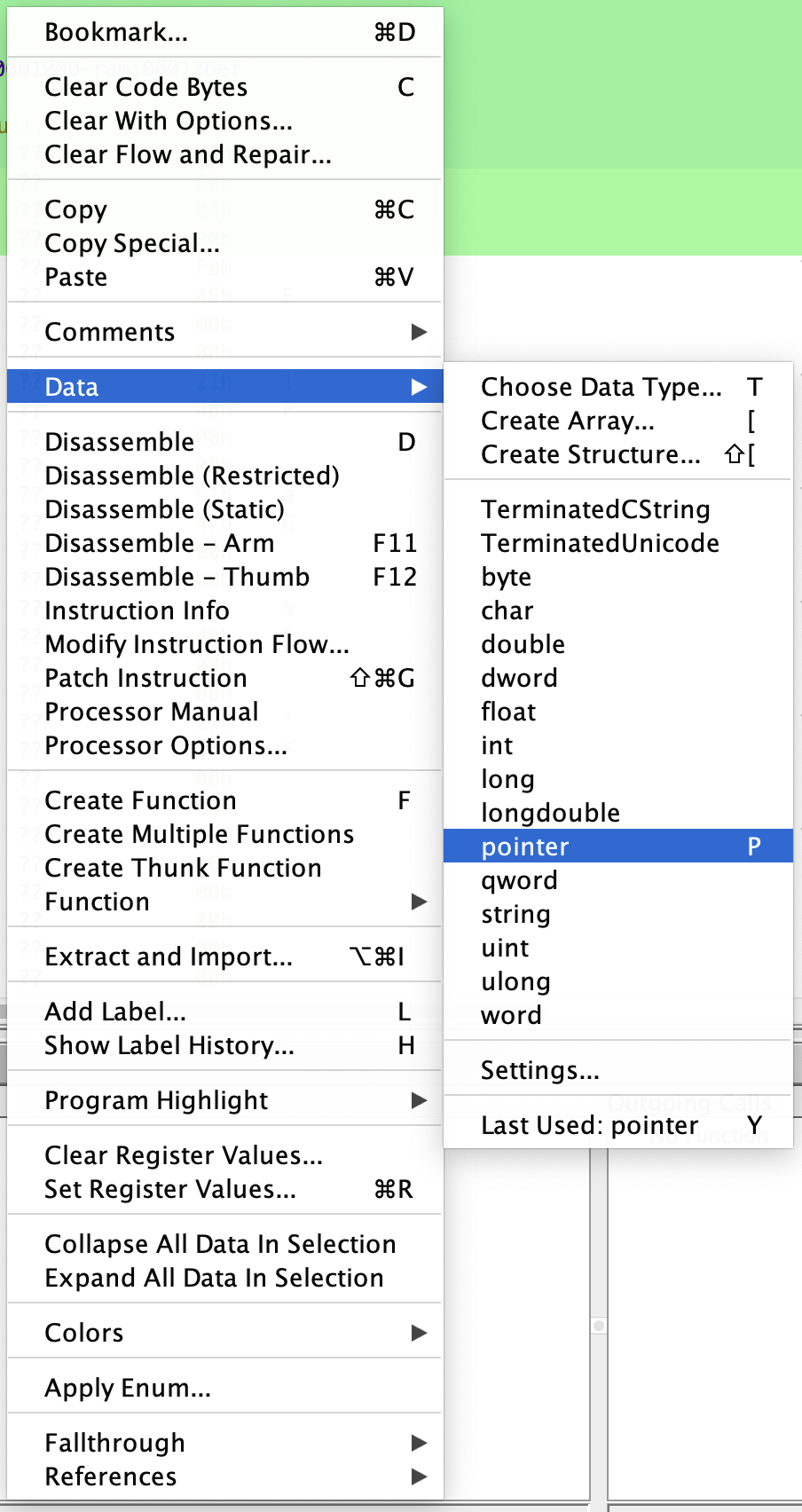
如果有连续的数据需要进行类型转换,可以使用 y 键重复之前的操作。
3.2 调用 Ghidra 的自动化分析引擎·
前面提到,打开 Code Browser 面板,Ghidra 会立刻询问是否要进行自动分析。因为我们的分析对象是 bin 文件,所以还需手动确定内存布局,所以笔者选择不在开始做自动分析。若文件是高级格式的可执行文件,如 PE、ELF,可直接点击允许分析。
分析引擎内置许多模块:
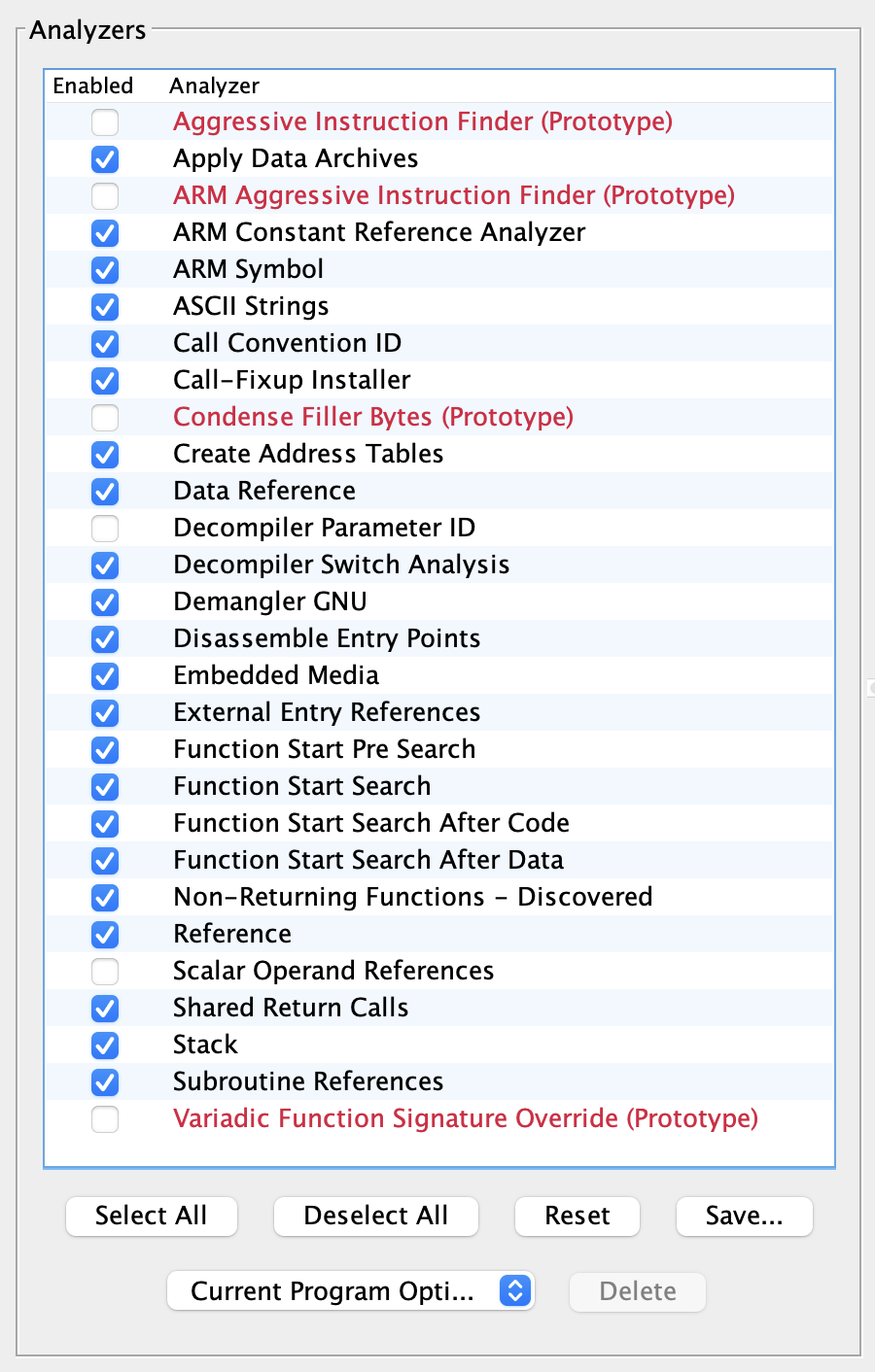
下面依次介绍:
- Aggressive Instruction Finder
- 在未定义的字节中找到有效代码,这些字节尚未被反汇编。
- 警告:除非已经找到了良好的代码,否则不应运行此功能。你必须检查结果,它可能会生成大量错误的代码!
- 这个分析器设计用于积极地在程序的未处理段中寻找可能被遗漏的有效指令。它尝试去解析那些初看似乎是数据或无意义的字节,以寻找隐藏的、未标记的代码。由于它在查找过程中可能会错误地将数据解释为指令,因此使用时需要格外小心,并且在应用结果之前进行仔细的验证和审查。这个工具特别适用于复杂的二进制分析任务,如恢复破损的代码或分析混淆的恶意软件。
- Apply Data Archives
- 基于程序信息应用已知的数据类型档案;
- 这种分析器利用预先定义的数据类型信息,自动识别和标记程序中的数据结构,如结构体、联合体、枚举等。这有助于逆向工程师更快地理解和导航程序的数据组织方式,特别是在处理包含大量复杂数据类型的大型软件时;
- 通过应用这些预定义的数据类型档案,可以提高反编译代码的可读性和一致性。
- ARM Aggressive Instruction Finder
- 积极尝试反汇编 ARM/Thumb 混合代码。
- 这种分析器专门设计用于处理 ARM 架构中常见的指令集交错使用情况,即 ARM 模式和 Thumb 模式的代码混合。通过积极地识别和反汇编这些混合模式下的代码,此工具能够帮助用户更准确地解析和理解在多种指令集模式下编写的复杂二进制文件。这对于逆向工程中处理由于编译器优化或特定编程技巧产生的混合指令集代码尤其有价值。
- ARM Constant Reference Analyzer
- 为通过多条指令计算出的常量引用提供 ARM 常量传播分析;
- 这种分析器专注于识别和解析 ARM 架构中由一系列指令共同定义和使用的常量值。它帮助逆向工程师理解如何在程序中通过多个步骤计算和引用这些常量,从而更好地分析程序的逻辑和优化决策。这对于深入理解复杂的算法实现或高级优化代码非常有帮助。
- ARM Symbol
- 分析 Thumb 符号的字节,并在必要时进行 -1 的位移;
- 这个分析器专门用于处理 ARM 架构中的 Thumb 指令集,它能够识别和调整 Thumb 模式下的符号,确保这些符号正确地对应于其在内存中的地址;
- 在 ARM 架构中,Thumb 指令集使用较短的指令长度来提高代码密度和执行效率,而这个工具可以帮助逆向工程师确保符号的地址计算考虑到这种特殊的指令编码。
- ASCII Strings:搜索有效的 ASCII 字符串,并自动在工程文件中创建。
- Call Convention ID:使用反编译器来识别未知的调用约定。
- Call-Fixup Installer:根据编译器规范安装 Call-Fixups,并修正任何调用不返回或 CallFixup 函数的功能。
- Condense Filler Bytes:寻找函数间的填充字节,并将它们合并。
- Create Address Tables:分析未定义数据以寻找地址表。
- Data Reference:分析由数据引用的数据。这种分析帮助识别程序中的数据结构之间的引用关系,例如指针、数组索引或数据结构的链接。这对于理解程序的内存布局和数据流非常关键。
- Decompiler Parameter ID:使用反编译器为函数创建参数和局部变量。警告:这可能需要相当长的时间!这种分析能够提升逆向工程的精确度,帮助理解函数的内部结构和行为,但由于其复杂性,执行时间可能会比较长。
- Decompiler Switch Analysis:使用反编译器为动态指令创建
switch语句。这种分析帮助识别和构造程序中的复杂控制流结构,特别是那些基于多重条件进行分支的switch语句,从而使反编译的代码更加清晰和易于理解。 - Demangler GNU:在函数被创建之后,此分析器将尝试对函数名进行重整(demangle),并为参数应用数据类型。这使得通过名称重整后的函数更易于理解,因为它们将显示为更接近原始源代码中的高级语言格式,包括参数类型和函数名称。这对于阅读和分析经过编译的代码尤其有用,特别是在处理 C++ 这类支持名称重整的语言时。
- Disassemble Entry Points:在新添加的内存中反汇编入口点。这个过程涉及识别程序内存中的入口点,如程序开始执行的地方或新加载模块的起始位置,并对这些位置的代码进行反汇编,以便更详细地分析程序的执行流程和行为。这对于逆向工程和安全分析来说是一个关键步骤,特别是在处理动态加载的代码或分析恶意软件时。
- Embedded Media:找到嵌入的媒体数据类型(例如 png, gif, jpeg, wav 等)。这个分析器识别和标记程序中包含的媒体文件,如图像、动画或音频数据,这对于理解程序如何存储和使用这些资源非常有帮助,也便于从二进制文件中提取媒体内容进行进一步的分析或使用。
- External Entry References:为已存在指令的外部入口点创建函数定义。这种分析帮助定义和标记那些从其他模块或外部库中调用的函数,确保在进行逆向工程时,能够正确理解程序与其它代码组件之间的接口和交互。这对于分析程序的外部依赖关系和行为非常重要。
- Function Start Pre Search:在进行任何代码反汇编之前,搜索特定于架构或编译器的模式,例如为处理
switch表和不返回的 ARM 函数的已知模式。这种预搜索能够帮助提前识别可能的函数起点,特别是那些有特殊行为或结构的函数,从而在之后的分析过程中提供更准确的反汇编和函数边界确定。这是一个预处理步骤,旨在优化后续的逆向工程工作。 - Function Start Search:搜索特定于架构的字节模式:通常是函数的开始。这个分析器通过识别典型的函数入口模式,如特定的汇编指令或序言(例如,为设置局部变量堆栈空间的汇编代码),来确定潜在的函数起点。这对于正确地映射程序的控制流和组织结构至关重要,帮助逆向工程师更准确地理解和分析程序的执行逻辑。
- Function Start Search After Code
- Function Start Search After Data
- Non-Returning Functions – Discovered:在代码反汇编过程中,发现函数不返回的迹象。当累积的证据超过一定阈值时,这些函数会被标记为不返回。如果在此分析器禁用或不存在时创建了函数,可以使用一次性分析操作来标记这些函数。这种分析对于理解函数如何影响程序的控制流非常重要,特别是那些可能导致程序异常结束或跳转到其他异常处理流程的函数。通过识别这些不返回的函数,可以更准确地分析和预测程序的行为,尤其是在涉及复杂的错误处理或多线程环境时。
- Reference
- 分析指令所引用的数据;
- 这个过程涉及识别程序中指令对内存地址、常量、或其他数据类型的引用,并通过这些信息帮助逆向工程师理解程序的数据流和控制流,从而更全面地分析程序的行为和结构;
- 这种分析对于确定程序如何与其数据交互,以及如何影响程序状态非常关键。
- Scalar Operand References
- 分析标量操作数,以寻找对有效地址的引用;
- 这种分析有助于识别程序中标量值(如整数或单个数据项)如何被用于访问或指向内存中特定位置的情况,从而揭示程序的内存访问模式和潜在的数据结构布局。这对于理解低级代码的操作和优化内存使用非常重要。
- Shared Return Calls
- 当分支的目标是一个函数时,将这些分支转换为调用,紧接着是一个立即返回。这种分析依赖于目标函数的创建,因此当这些函数在此分析器被禁用或不存在时创建,可以使用一次性分析操作来应用此转换。
- 这种处理方式有助于优化和简化函数调用和返回的处理逻辑,特别是在处理那些被多个地点共享的返回点的情况。通过将这些分支转换为调用加返回的结构,可以更清晰地表示程序的控制流,使得程序的逻辑更加直观和易于理解。
- Stack
- 为函数创建堆栈变量。这种分析有助于识别和定义函数中使用的局部变量和参数,这些变量和参数通常在函数的堆栈帧内分配和管理。通过这样的分析,可以更清楚地看到函数如何操作其内部数据,以及这些数据如何影响函数的行为和程序的执行流程。这对于理解函数的内部结构和逆向工程整个程序至关重要。
- Subroutine References
- 为被调用的代码创建函数定义;
- 这种分析有助于识别和标记程序中的子程序调用,确保每个被调用的代码段都被适当地识别为独立的函数。这使得反编译的代码更加模块化和清晰,便于理解各个函数之间的关系和程序的整体结构。
- Variadic Function Signature Override
- 检测每个函数体中与当前选择交叉的可变参数函数调用,并解析它们的格式字符串参数以推断正确的签名。目前,这个分析器仅支持
printf、scanf及其变体(例如snprintf、fscanf)。如果当前选择为空,它将搜索每个函数。一旦推断出正确的签名,就会覆盖它们。 - 这种分析器特别用于处理那些使用格式化字符串来传递多个参数的函数调用,这些函数调用的参数数量和类型在编译时不是固定的,而是在运行时确定。通过正确解析和应用这些签名,可以提高逆向工程结果的准确性,特别是在涉及字符串格式化和数据输入/输出的场景中。这有助于更好地理解程序的行为和潜在的安全漏洞。
- 检测每个函数体中与当前选择交叉的可变参数函数调用,并解析它们的格式字符串参数以推断正确的签名。目前,这个分析器仅支持
3.3 查看函数的交叉引用·
交叉引用在分析函数调用、数据引用方面具有极为重要的地位。与 IDA Pro 不同,Ghidra 的交叉引用以固定窗口的形式呈现,如下图所示。这非常类似其反汇编窗口的固定呈现形式,或许 Ghidra 的设计者喜欢用超大的屏幕做分析,所以不吝惜屏幕的空间。反过来说,如果屏幕够大,将所有的窗口都开启,效率将大大提高。
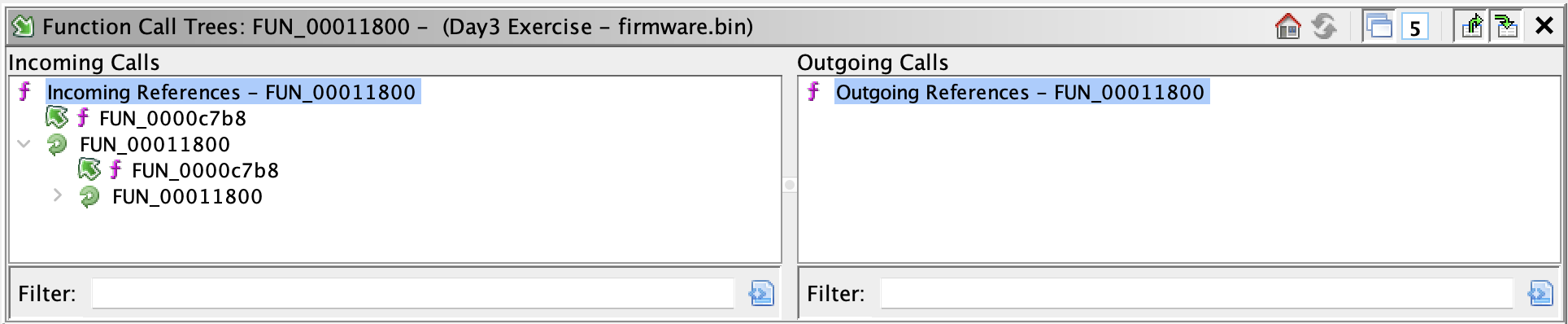
在该窗口中,交叉引用分两个方向:
- Incoming Calls,即调用了本函数的函数列表,对于调用者,还可以递归地查看其调用者,乃至调用者的调用者。如果遇到自调用的递归形式,将产生无穷无尽的调用链。由此可以方便地反向追踪调用函数;
- Outgoing Calls,即被本函数调用的函数列表。调用具有发散性(即以本函数为根,其他函数为分支,将产生一棵庞大的树),所以该表的表项不具备递归性质。





