坑边闲话 :容器技术是存储、网络、计算的集合体。换言之,要想使用好容器,需要对容器的存储、网络、计算模型有比较丰富的经验。本文介绍在 Linux 系统上部署多个容器服务时可以使用的方案。
1. 思考几个问题·
首先,在单机部署十几个乃至数十个容器之前,我们先考虑一下有可能遇到的问题。
容器本质上就是服务,服务的存储该如何组织,实现安全、高吞吐、低延迟。
如何组织网络才能使网络架构更简单易用?
如果容器需要较为稳定的性能发挥,应该如何设置 CPU / GPU 资源?
2. 应对方案·
2.1 存储性能·
现在大部分容器都使用数据库技术,数据库和普通存储不一样。一般来说,数据库处于文件系统和应用程序之间。
数据库会向文件系统申请较大的单一文件存储自己的所有表。因此数据库的存储粒度是「自行管理」的。虽然看上去 .db 文件很大,但是数据库操作基本上也是小粒度的随机 I/O.
如果底层文件系统的逻辑块大小非常大,每次数据库读写的时候将会带来极大的写放大效应。因此,数据库的底层 I/O 应当和 MP4/MKV 等影音类型有所区别。
如果数据库的 recordsize 被设置的很大,如 128KiB,那么一次 8KiB 的读取,就会「拔出萝卜带出泥」,需要先从硬盘读取 128KiB 左右的数据,然后从里面取出 8KiB. 当然,如果你使用的是 EXT4 这种简单的文件系统就不需要考虑这个问题了,然而,EXT4 的问题更大。
笼统地说,容器的存储应该有以下特征:
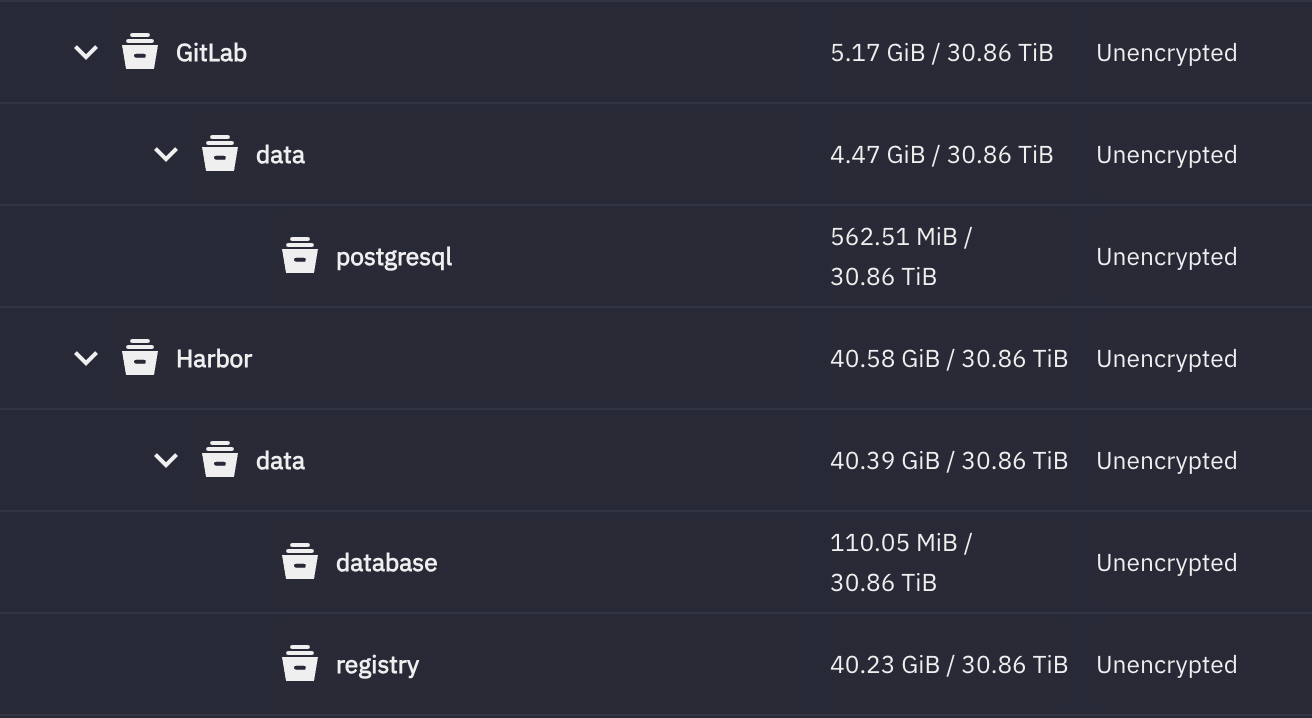
容器使用独立的目录或者 ZFS dataset / BtrFS subvolume. 而且需要对数据库、影音库设置不同的参数,以优化存取带宽,降低延迟。
容器最好使用 CoW 文件系统,这样会更容易地进行快照操作。
最后讲一下,为什么一个容器的存储要使用一个独立的 ZFS dataset 或 BtrFS subvolume?
我们考虑一个场景,Jellyfin 在升级的过程中,可能需要对数据库做转换,而这是一个非常危险的操作。如果你使用 jellyfin/jellyfin:latest 镜像,而且打开了自动更新,那么下次 docker compose up -d 的时候,就会自动使用最新的镜像,然后触发意料之外的数据库大更新。一旦失败,数据库可能也无法回滚,结果只能是重建数据库,背后的辛酸可想而知。如果可以执行细粒度的快照,这个问题将会不复存在,出问题直接回滚即可。
2.2 网络隔离·
容器使用的网络命名空间技术也比较复杂。
网络命名空间指的是一个独立的网络堆栈环境,它拥有自己的网卡、IP、路由、iptables,这样会形成比较干净、安全的独立网络环境。即使两个容器在同一台物理机,只要在不同的网络命名空间里,它们就像在不同网络里一样,互不可见。
Docker 的网络是构建在 Linux 网络命名空间之上的:每个容器都有一个 独立的 network namespace,Docker 网络负责把这些 namespace 连接起来 。
1 2 3 4 5 6 7 8 9 10 [ Host namespace ] | | veth pair (虚拟网线) | +---------------+ +---------------------------+ | docker0 bridge| <-------> | veth0 (in container) | +---------------+ | Network Namespace | | eth0 + IP + Route + FW | +---------------------------+
使用下列命令,可以创建一个 Docker 网络,并创建一个对应的 Linux 网络 interface.
1 docker network create --ipv6 --subnet 2001:0DB8::/112 reverse_proxy
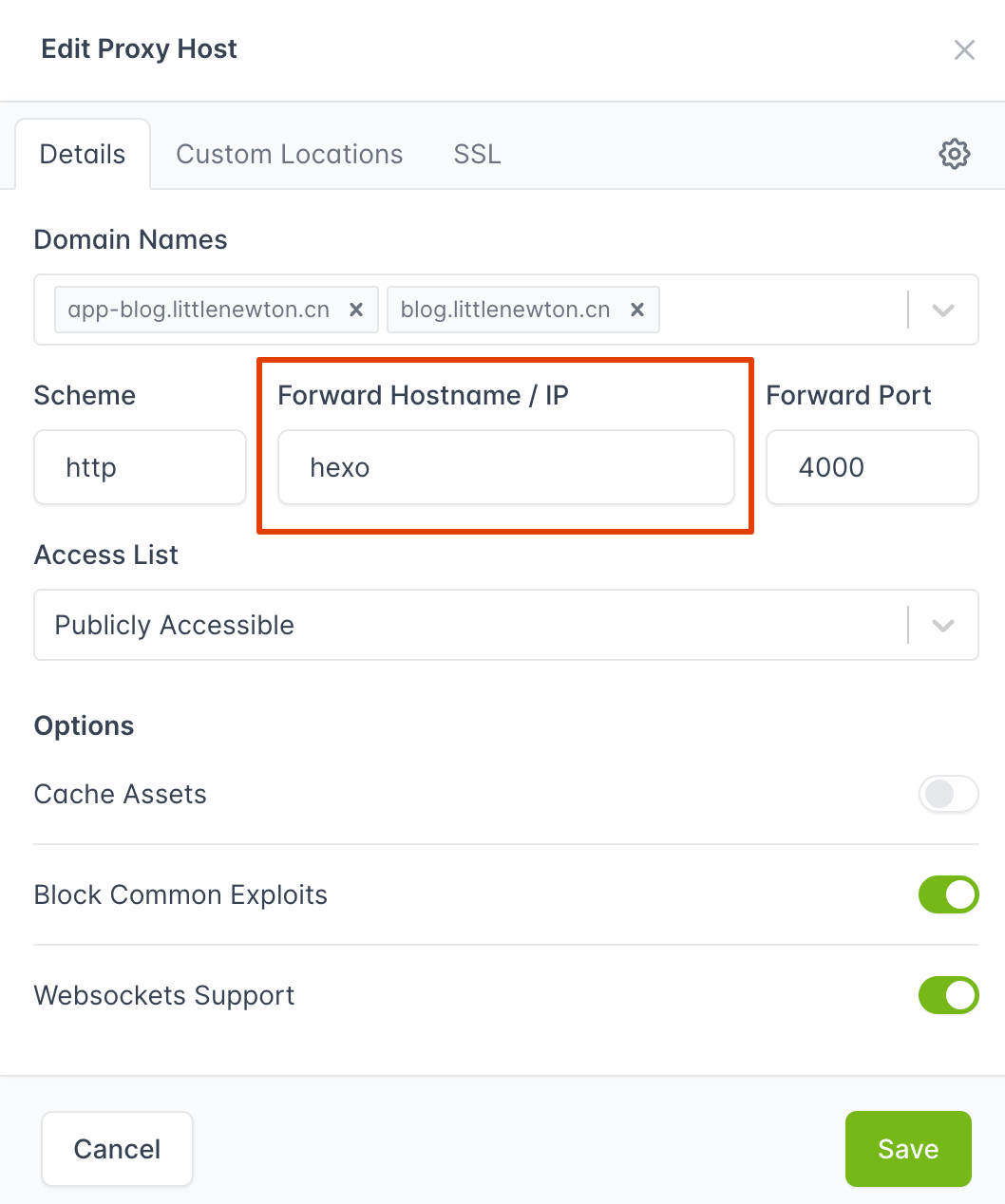
并让 hexo 和 nginx 容器挂载到这个网络里:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 services: hexo: image: littlenewton/hexo:latest container_name: hexo hostname: hexo environment: - HEXO_SERVER_PORT=4000 - GIT_USER=LittleNewton - [email protected] - TZ=Asia/Shanghai volumes: - ${APPDATA_PATH}/Hexo/blog:/app networks: - reverse_proxy restart: unless-stopped nginxproxymanager: image: "jc21/nginx-proxy-manager:latest" container_name: "nginxproxymanager" hostname: nginx-proxy-manager restart: unless-stopped privileged: true networks: - reverse_proxy ports: - "80:80" - "81:81" - "443:443" volumes: - ${APPDATA_PATH}/NginxProxyManager/data:/data - ${APPDATA_PATH}/NginxProxyManager/letsencrypt:/etc/letsencrypt networks: reverse_proxy: name: reverse_proxy external: true
由于每次重启,容器都会被分配不同的 IP,甚至其网段也会小有变化。因此如何在容器里做反向代理就非常令人头疼 。
写 IP 地址会变化,导致反向代理失效;
设置静态 IP,相对比较繁琐。
问题其实很简单:什么都不需要操作,在 Docker 的自定义网络(比如刚才创建的 reverse_proxy)里,容器之间可以通过容器名进行 DNS 解析。
比如,我们在 NginxProxyManager 里,可以通过 hexo 这个容器名字,找到 hexo 容器的 IP 地址。而且,我们不需要手动设置任何 DNS 解析!
1 2 3 4 5 6 7 8 9 [root@docker-nginx-proxy-manager:/app]# nslookup hexo Server: 127.0.0.11 Address: 127.0.0.11#53 Non-authoritative answer: Name: hexo Address: 172.18.0.4 Name: hexo Address: 2001:db8::4
2.3 绑定 CPU 核心·
2.4 NVIDIA 容器运行时·
本文以最常用的 NVIDIA 独立显卡为例,讲解如何使用 NVIDIA 设备做加速。
2.4.1 加速场景·
部署 AI 推理服务
部署媒体服务器,实现编解码加速
2.4.2 安装 NVIDIA runtime·
一般来说,最朴素的做法就是把 NVIDIA 的 GPU 设备以文件路径的方式透传给容器。然而这么做有个巨大的弊端:需要在容器里装一遍显卡驱动!这就非常难受了。NVIDIA 的 GPU 驱动非常庞大,安装一遍可能得很久,而且很多容器镜像并没有集成 NVIDIA 驱动。那么怎么处理才好呢?
NVIDIA container-toolkit 解决了这个麻烦!
它的原理大约是(并不准确)把 GPU 驱动目录映射给容器,这样容器里就可以看到驱动文件,自然就省去了安装驱动的步骤。听上去非常简单,但是后面是很多工程师掉了许多头发才最终实现的。其实,NVIDIA container-tookkit 的核心思路是驱动不进容器,容器访问宿主机的驱动 。
安装 toolkit 后,Docker 会出现一个新 runtime: nvidia-container-runtime. 然后执行 docker run --gpus all nvidia/cuda:12.2-base 之后,Toolkit 会做三件事:
自动把 /dev/nvidia* 挂载进容器
自动把驱动的用户态库 /usr/lib/x86_64-linux-gnu/libnvidia-ml.so, /usr/lib/x86_64-linux-gnu/libcuda.so 从宿主机挂载进容器
注入 GPU 相关环境变量。
因此,容器不用安装驱动,只需要 CUDA Runtime(用户空间 API,如 libcudart.so)。如此一来,Toolkit 解决了 user-space driver 注入的路径问题和 runtime 自动挂载问题。
安装命令 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 sudo apt-get update && sudo apt-get install -y --no-install-recommends \ curl \ gnupg2 curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \ && curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \ sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \ sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list sudo apt-get update export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.18.0-1 sudo apt-get install -y \ nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \ nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \ libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \ libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}
安装完之后,需要切换一下 runtime 并重启 Docker 服务:
1 2 sudo nvidia-ctk runtime configure --runtime=dockersudo systemctl restart docker
随后测试能否在容器里使用 GPU:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 $ docker run --gpus all -it --rm debian:trixie nvidia-smi Sat Nov 8 12:24:37 2025 +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 580.105.08 Driver Version: 580.105.08 CUDA Version: 13.0 | +-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 3090 On | 00000000:AF:00.0 Off | N/A | | 30% 31C P8 12W / 350W | 4MiB / 24576MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ +-----------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=========================================================================================| | No running processes found | +-----------------------------------------------------------------------------------------+
本文简要介绍了如何在单机环境部署一个优雅的容器执行环境,涉及存储、网络、计算三大板块。