ZFS NVMe 全闪存储性能优化
坑边闲话:ZFS 要发挥出最好的性能,离不开专家优化。本文介绍 ZFS 在资源充足情况下的优化方式。
1. NVMe 阵列要配置强大的多核 CPU·
ZFS 目前的物理磁盘块分配模型与 NVMe 多队列、队列深的特性不能兼容,因此丑话说在前面:CPU 一般的情况下,很难把 ZFS RAID-Z 的性能优化到特别强,比如发挥出 PCI e 4.0 x4 ZFS member 50% 性能。
NVMe 协议与 CPU 核心的环形队列机制密切相关。它通过 SQ 和 CQ 实现主机与控制器间的高效通信,每个队列为环形结构,可绑定到特定 CPU 核心。环形缓冲区的特点就是能减少锁竞争与中断延迟,实现多核并行 I/O 处理。然而,NVMe 软阵列性能依赖 CPU 多核并行处理能力。每个 NVMe 队列通常绑定一个核心,负责提交与完成 I/O,核心数量太少会导致多个设备和队列争夺同一核心资源,产生上下文切换和中断延迟,无法大规模并行处理请求,最终使 IOPS、带宽显著下降,阵列性能受限。
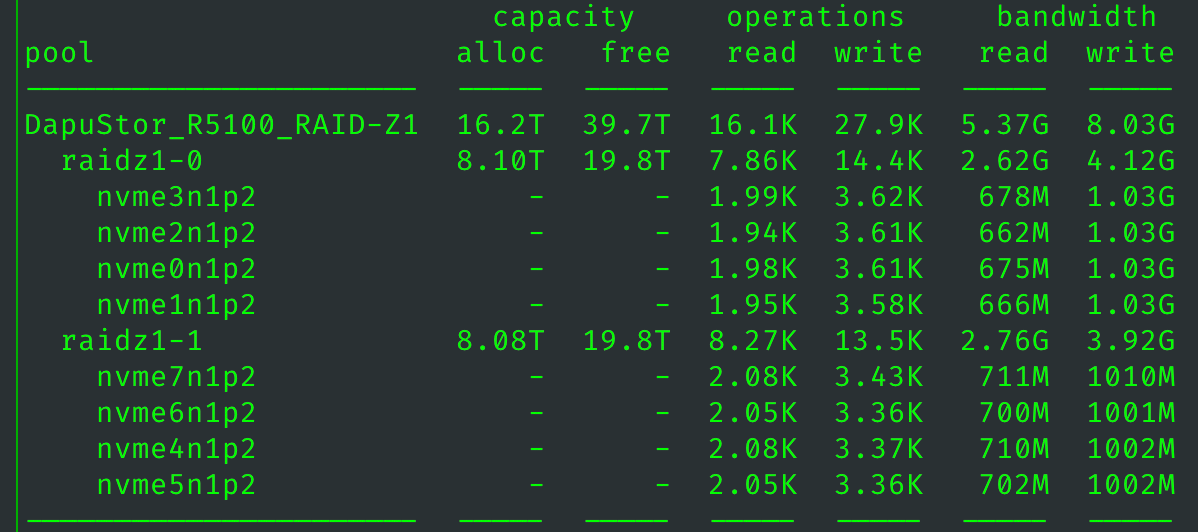
如图1所示,EPYC 7302 这种弱鸡的胶水核心,最多也就能发挥出一个 Gen4 盘六分之一的性能。一个实际只有 Gen4x4 6盘上限的系统,理论带宽上限是 36GB/s, 实际只有 8GB/s. 如果换一颗更强大的 CPU,估计能达到 10-12 GB/s, 虽说足够应对绝大多数存储场景,但是距离理论上限还是非常遥远的。
此处建议在给 open-iscsi, smbd, nfs-server, NIC, SAS-RoC 等留足核心(比如8核)之后,再给每个 NVMe 至少 1 个核心。比如,
- 一个 8 盘 NVMe 系统
- 挂着几十个 SATA/SAS 机械盘
- 有一个高速以太网卡
- 跑着一堆文件系统共享、块共享服务
建议至少准备 32 个纯大核的 CPU.
2. 升级最新的节流算法·
目前 openzfs 的块分配和节流算法也不是很兼容 nvme 硬盘。
旧的分配节流机制存在以下严重缺陷:
- 基于请求数量的节流:使用I/O请求数作为节流单位,但块大小范围从512B到16MB,导致预测不准确。在I/O聚合场景下,32-100个请求可能聚合成几个,设备利用率不足。或反之可能排队高达1.6GB的写入数据。
- 破坏了空间平衡机制:过度追求性能优化,导致vdev空间使用严重不平衡。使用率高的vdev更早碎片化,满盘后完全停止写入。添加新vdev后,需要极长时间才能恢复平衡(除非旧vdev因碎片化已明显变慢)
- 缺乏灵活性:无法在需要时追求速度和空闲时平衡空间之间智能切换
目前社区有个来自 TrueNAS 团队的提交,能初步解决写入节流问题:
虽说与直接优化后段分配器距离比较远,但是这个新分配器也能在一定程度上提升写入性能。
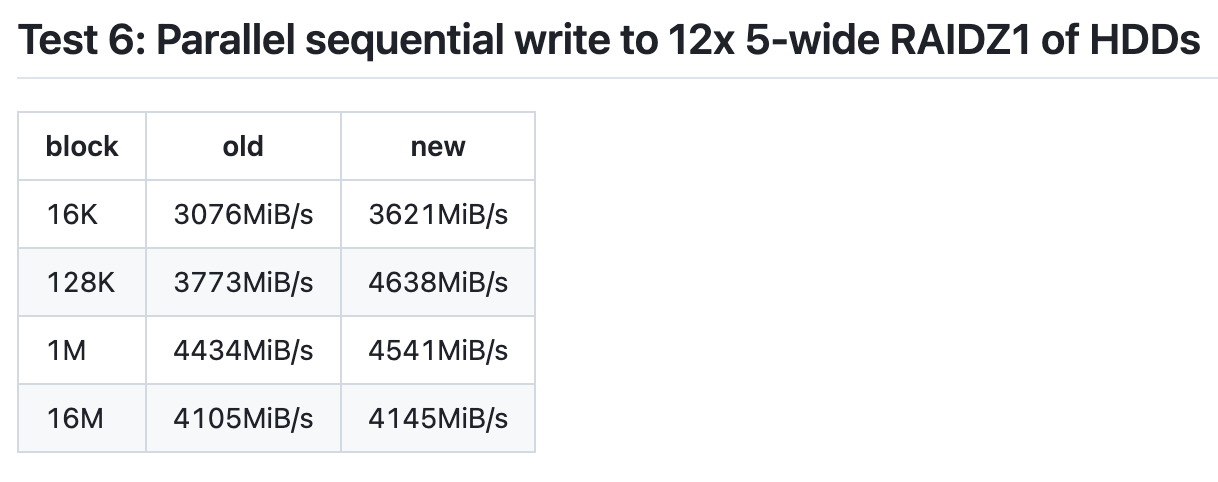
根据开发者 Alex 的测试,机械阵列用了新算法之后,1MiB 以上的 recordsize 场景下,总体区别不大,但是对于常规的 128KiB 场景,写入性能提高了 23%,进步不可谓不明显。同样的算法应用于 nvme 阵列应该也能带来很大的性能提升。
3. 未来的方向·
社区目前已经注意到了 ZFS 后端分配模型与 NVMe 介质之间的深刻矛盾。此前介绍的 direct-io 已经初步支持了缓存绕过,但是直接访问 nvme 就涉及到块对齐问题。然而众所周知,zfs 推荐默认开启 lz4 压缩,一个具体的块压缩完是多大几乎无法提前预测,所以很多 O_DIRECT flag 的写操作由于不对齐,会默认退回到 buffered_io, 这是所有文件系统都要面临的问题。
要点是三个层级的“对齐”:
- 用户态缓冲区地址必须与 CPU 页边界(通常 4 KiB)对齐。因为 DMA 只能映射整页物理内存;如果用户缓冲区起点不是页对齐,DMA 控制器无法正确映射。
- 文件偏移量 file offset 必须是块设备逻辑扇区大小(通常 512B 或 4KiB)的整数倍。因为块设备不能从半个扇区开始写,也不能只写某个字节。NVMe 的 LBA 通常是 4KiB,对齐就是 4096 字节。
- I/O 长度也必须是扇区大小的整数倍。否则会导致 DMA 读/写跨越未对齐的块,破坏设备原子性。
普通的 buffered I/O 中,内核页缓存可以帮你做对齐修正。比如写 13 字节,它会落入页缓存中一个 4KiB 页里,由内核稍后对齐、合并、写回。但 O_DIRECT 明确要求不使用页缓存。如果不对齐,内核就得分配临时 bounce buffer 来补齐、复制数据,而那样就违背了 Direct-IO 的初衷。所以内核干脆拒绝执行,返回 EINVAL。
其实压缩之后对不齐才是正常的,对齐只是偶发事件。
如果有办法让压缩算法让让路,比如生成填充对齐字节之后的对齐压缩块,理论上能大大提高 Direct-IO 的成功率。对于高吞吐、低延迟 NVMe 场景,这是非常划算的权衡。
4. 围观大佬·
老湿基的偶像 Allan Jude 和 Tom 做了一场对话,非常之精彩。推荐所有人去看一看,哪怕不能完全看懂。这两位都是非常有品味的工程师,对存储系统有很深刻的见解。
- 国内观看:BV11Ynjz4E3h
- 视频原版:YouTube