ZFS 记录值很重要
坑边闲话:recordsize 是个理解上限和下限都很不平凡的概念,普通人可能认为大文件连续吞吐用大的 recordsize,小吞吐、改写就用小 recordsize,然而这并不够深入,甚至在某些场景下会造成误解。
1. 深入理解 recordsize·
recordsize 并不是一个具体的概念,而是在将 dirty page 往磁盘同步时,采用的最大分片值。因此,使用大的 recordsize 会导致分块数量变少,占用的指针数量也变少,但压缩空间变大容易达成更高的压缩率。
然而,如果要对某个文件进行改写,大的 recordsize 极有可能造成恶劣影响。比如一个数据库的 .db 文件有 10GB, 但是一次只改写里面 8KB 的数据,这时如果使用了 128KiB 的 recordsize,将导致要先读出其中 128KiB 的连续内容,然后改写其中的 8KB 数据,最后申请 128KiB 的新空间并把改完的内容写进去。由此可见,一次 I/O 就造成了 128/8=16 倍的写放大。
之前我反复强调 recordsize 对 ZFS 存储占用的影响,今天有个很好的例子可以展现这一点,如图所示,4K 块的真实占用比 16K 模式多几十 GB,128K 模式要更明显。
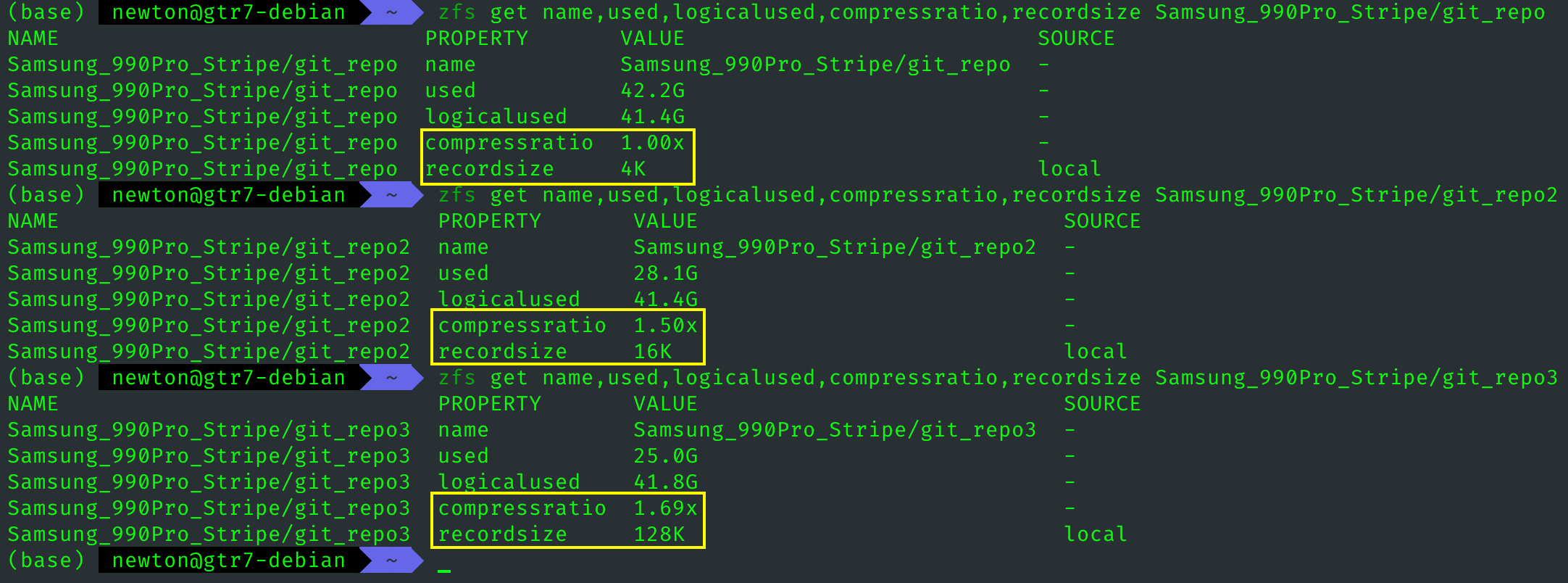
原因如下:ZFS 需要对每一个record 生成一个块指针,然后写入到 dnode(类似 inode),这个指针结构体是 128字节。所以,4K 模式的块指针数量是 128K 模式的 32 倍。
此外,压缩算法是在逻辑块内压缩,4K 块的可见范围较小,压缩起来没有大块效率高,所以压缩率上也会吃亏。
那么 4K 块的优势是什么呢?我想不太出来。毕竟是压缩型文件系统,写入时 4K 对齐这件事本身就很有难度,用小块提升小文件吞吐性能可能收益有限。而且 DMU 和 ZIO 子系统会把近期写入在虚地址和物理地址上尽量做到连续分布,以便充分利用 ARC 的读优化。所以我的结论就是保持 128K 默认设置就挺好。
如果 zdb 有办法监控某个负载(比如编译、数据库IO)的块存取顺序,然后进行物理块重排序,应该会有立竿见影的性能提升。但是这打破了存储不干涉应用层的规矩。