ZFS 存储教程 p2:优化、备份与共享
坑边闲话:本文前作已经较为细致地讲解了 ZFS 的很多基础原理,包括卷管理以及部分性能优化。本文从缓存、快照、权限管理、迁移备份入手,讲解一些很常见的高级操作。
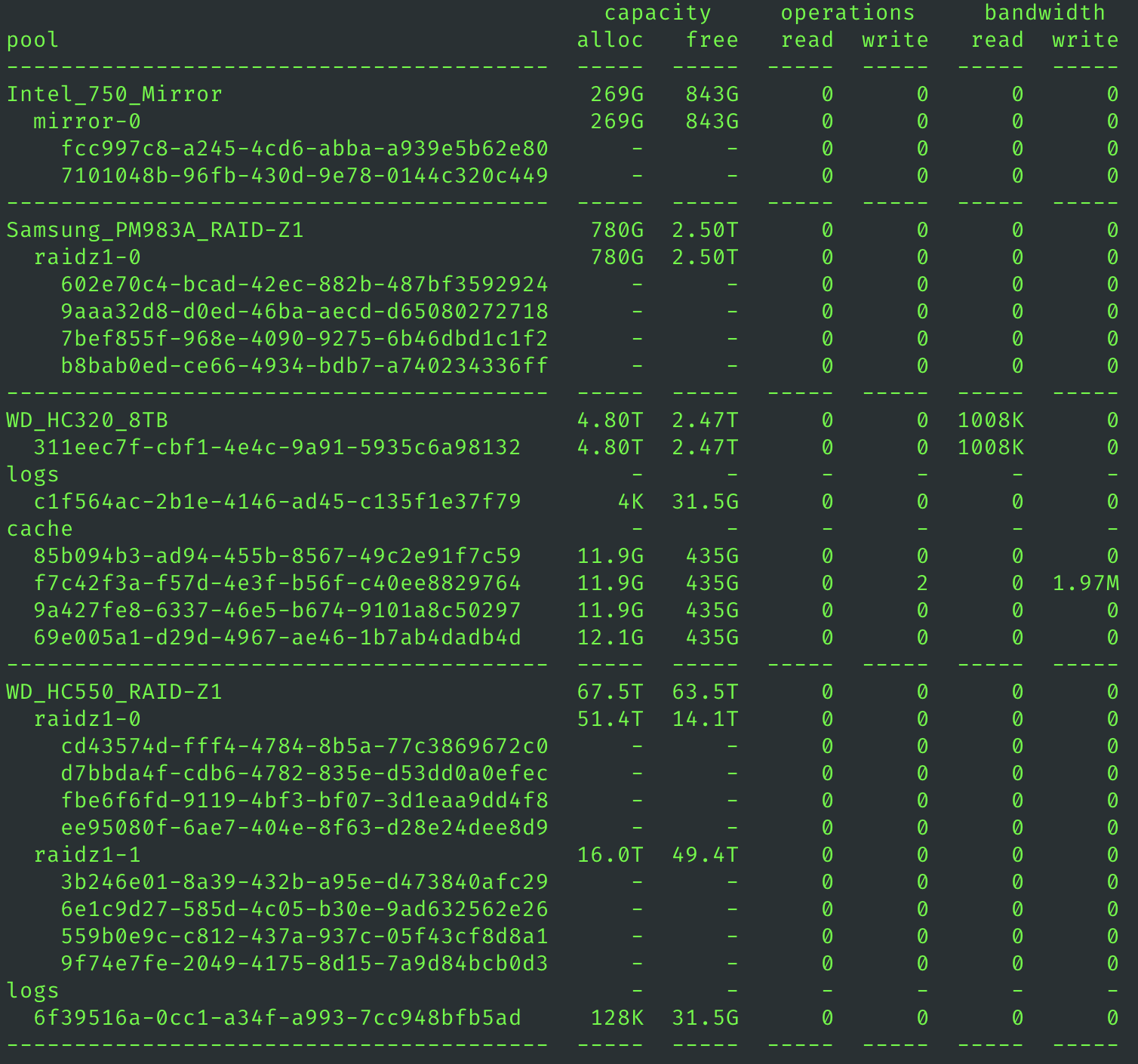
1. ARC 与 L2ARC:是否有必要用 L2ARC 呢?·
1.1 到底什么是 ARC 读缓存·
ZFS 中的读缓存即 ARC,他是一种采用了适应性技术的智能读缓存。传统的 LRU 算法在块存储上是存在问题的,ARC 能很好地解决 LRU 和 LFU cache 策略的问题。但是要注意,所有的 cache 都是打擦边球,妄图以小聪明解决某些性能瓶颈,诚然这种小聪明有时候效果很明显,但是一旦你的使用场景与设计者的预设不同,那么必然遇到缓存失效问题。一旦失效,有缓存还不如无缓存。
ZFS 的 L2ARC 是很常用的功能,特别多见于内存容量不是超级大但是会对某个大工程做频繁读取的工作。比如多人剪辑视频。
注意⚠️:L2ARC 算是一个锦上添花的功能,特别是对单用户场景,L2ARC 并不具有明显优势。
L2ARC 中的 2 就是第二层的意思,而不是 L to ARC(L 到 ARC),它实际上就是一个缓存。ZFS 认为内存中的 ARC 可能不够多,无法放下所有的热数据,但是直接访问机械阵列就需要很大的延迟,所以可以在 ARC 和 pool 之间放置一个中间层,这就是 L2ARC. 既然是缓存就必然涉及缓存策略,首先要明确,L2ARC 和 ARC 是互斥的,也就是说同一个数据 block 不会同时出现在 L2ARC 和 ARC 里,只有从 ARC 溢出的块才有有可能进入 L2ARC.
2. 快照与 Copy-on-Write·
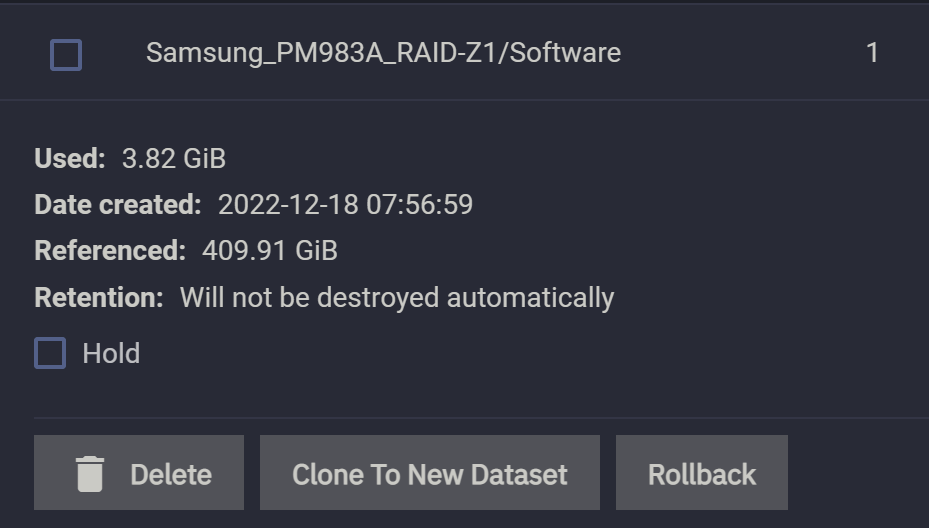
快照有两个重要参数:
Used:快照本身所占据的体积。Referenced:快照所笼罩的文件的体积。
2.1 Copy-on-Write思想·
Copy-on-Write,中文一般翻译为写时拷贝,下称 CoW. 当我们要写入新的 block 时,可直接让 Allocator 分配器给我们分配空间。CoW 一般指修改 Block. CoW 指的是不直接修改原有 block,而是直接创建新 block,把要修改的东西写到新的 block 里,并修改指针的指向。CoW 的一个表现就是把随机写入变成了顺序写入,因此 ZFS 的写入性能是很高的。然而,在读取的时候就麻烦了,因为把随机写变成顺序写,因此原先逻辑上有空间顺序性的布局被打散了。所以,ZFS 的读性能一般比不过写性能。随机写变成顺序写,但顺序读变成了随机读。
2.2 快照计算:以文件增删为例·
文件增删指的是以文件为单位进行增加、删除。粒度相对较粗,模型统一,且分析起来比较简单。
先在 pool 的初始状态下创建一个快照,命名为 1(见图 1 右上角):
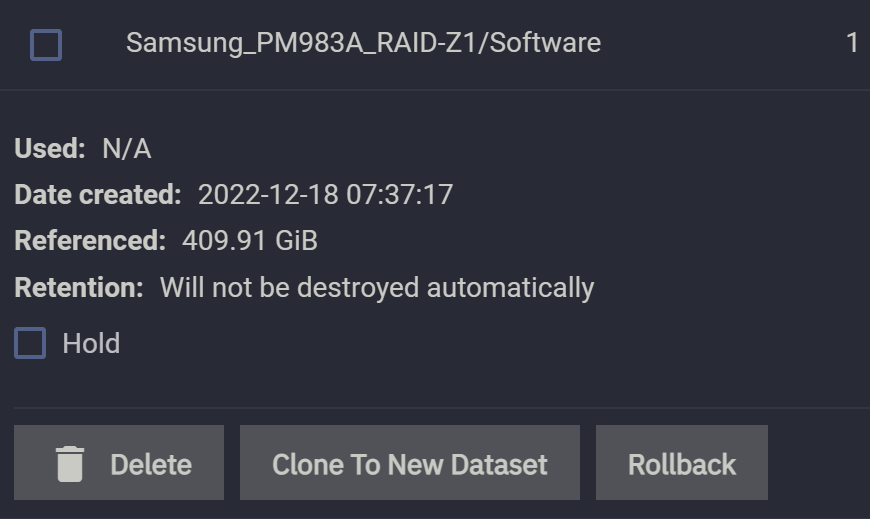
然后我们往这个目录里写入一个 10GiB 的文件,发现快照的 Used 大小还是几乎还是 N/A,说明新加入文件并不会导致原有快照与新文件等体积地增大。
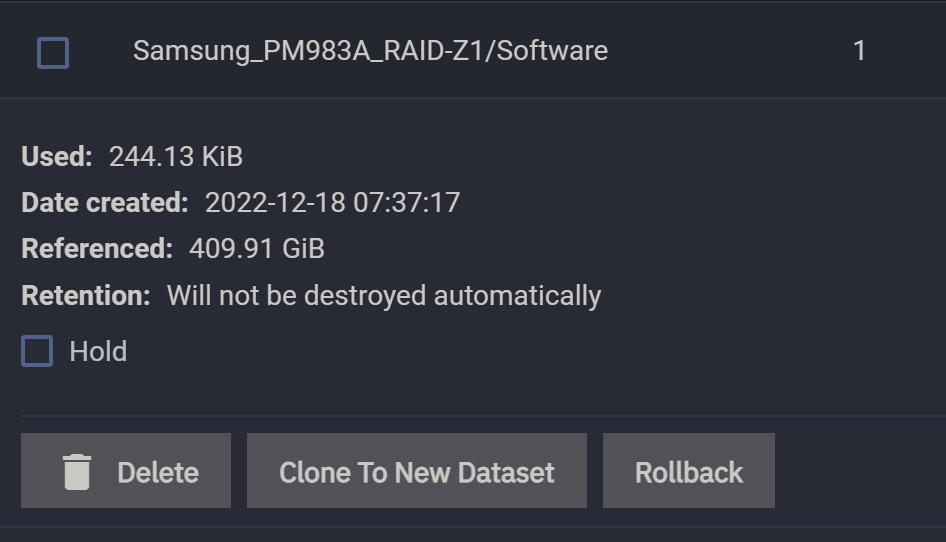
随后我们再创建一个快照,命名为 2:
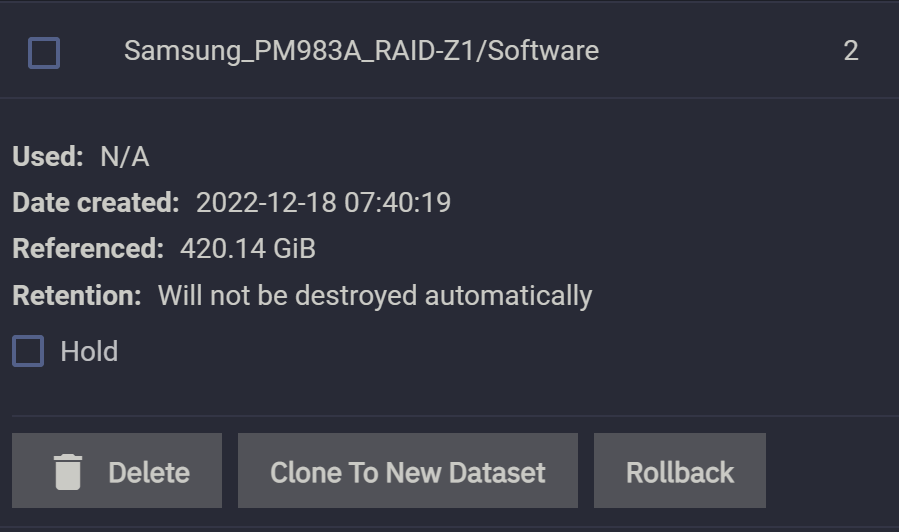
快照 2 的“笼罩”范围 Referenced 由上一个快照的 410GiB 变成了 420GiB,这是因为我们新加入的体积为 10GiB 的文件被这个快照 2 所“笼罩”了。
现在我们删除这个 10GiB 的文件并再次查看所有快照:
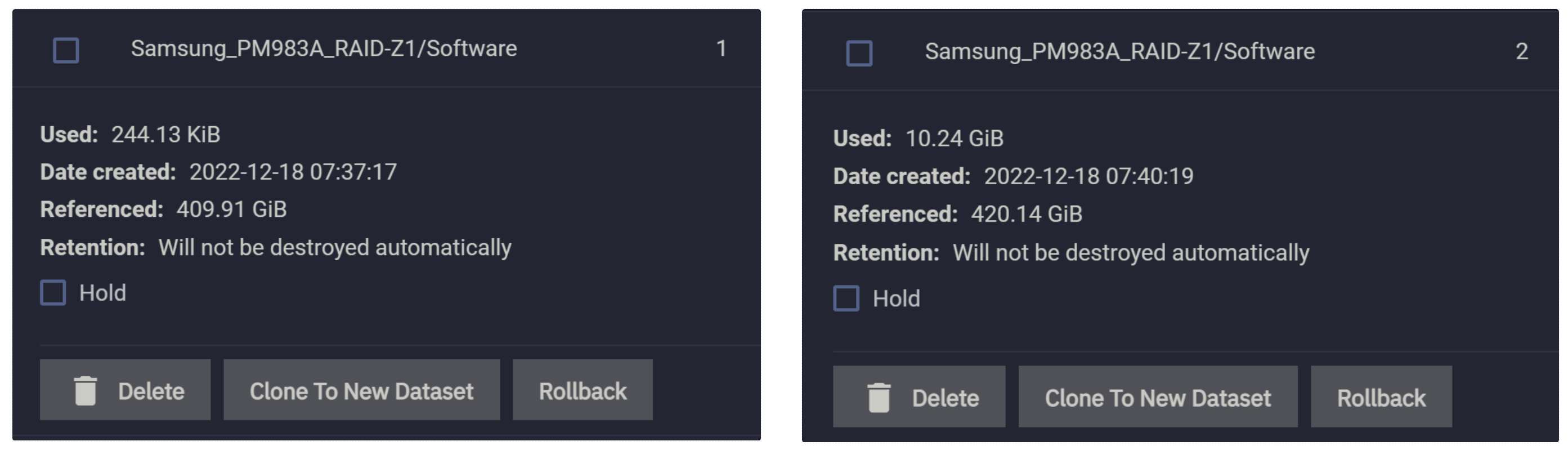
观察发现,快照 1 的 Used 保持不变,但是快照 2 的Used变为了 10GiB,这说明快照的 Used 值只会在它“笼罩”之内的的数据发生更改时才会产生变化,而且是改多少就增加多少。这就是 Copy-on-Write 的表现。
注意!我们这里是以文件为单位删除做演示,实际工作中会对某文件进行编辑,比如 Open 之后再 Write,最后 Close,这一套 I/O API 走下来,文件中的某些结构被修改,反映到文件系统里就是某些 Block 块被改了,这些块就被 Copy-on-Write 地记录了下来,反映到快照里就是快照的 Used 体积有所增加,增加的值就是被改的 Block 体积之和。由于编辑大的二进制文件不好演示,我们这里用文件增删做 demo,不影响理解。
由此可见,如果你只是一味地往 dataset 里添加新数据,那么完全可以一秒钟一个快照,因为这基本不会带来任何存储上的压力。
2.3 快照计算:以文件修改为例·
文件修改指的是以文件块(block)为单位进行增加、删除。粒度相对较细,由于编辑软件不同,文件修改表现出来的差异化较大,且分析起来比较复杂。这里我们使用两个软件对同一种文件进行编辑,观察差异性。
如果你经常对某个 dataset 里的大文件进行增删改查,那就需要注意体积了。不过也无需太过担心,毕竟快照是 block 级别的,只要你的二进制文件的数据结构具有良好的存储局部性,那么也不会带来很大的存储压力。
2.3.1 Abbyy FineReader v.s. Adobe Acrobat Pro DC·
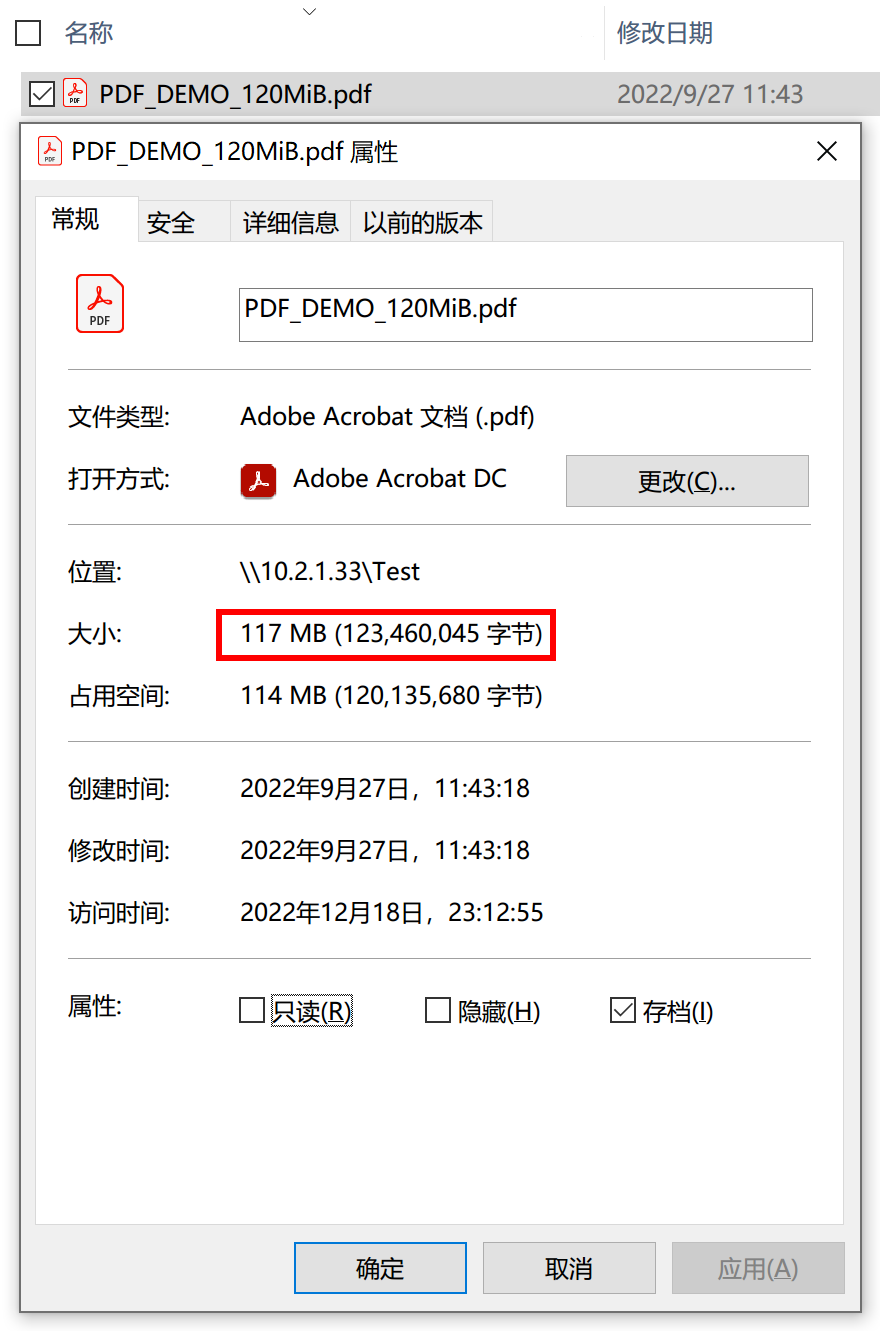
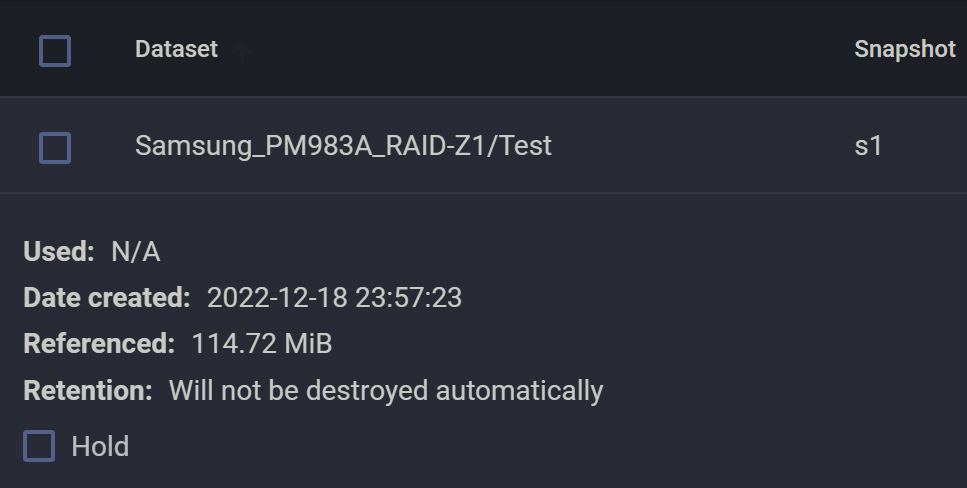
先创建一个测试用的 dataset,命名为 Test,并在里面存入一个约 120MiB 的文件。

随后,创建快照 s1.
然后我用 Abbyy FineReader PDF 编辑器删除其中一半左右的页面,模拟日常操作。
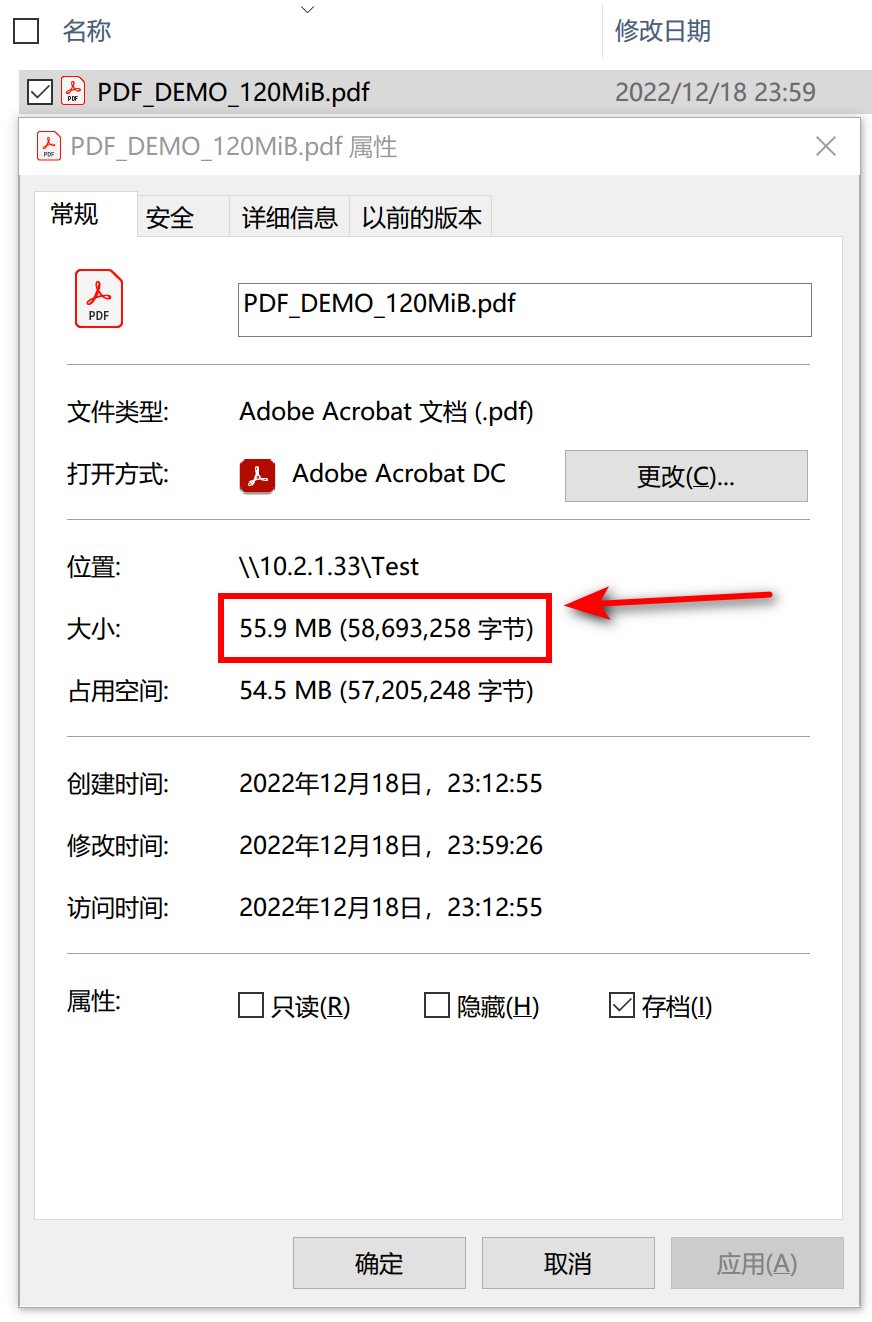
由于修改了数据,所以快照应该有所变化:
按照我们的理解,ZFS 是 Copy-on-Write 的,所以删除文件中的 blocks 只会让 ZFS 在存储日志里记录一下删除事件,并不会导致实际空间被删除。同时,因为没有新 Block 被占用,所以 ZFS 的快照也不会增加。
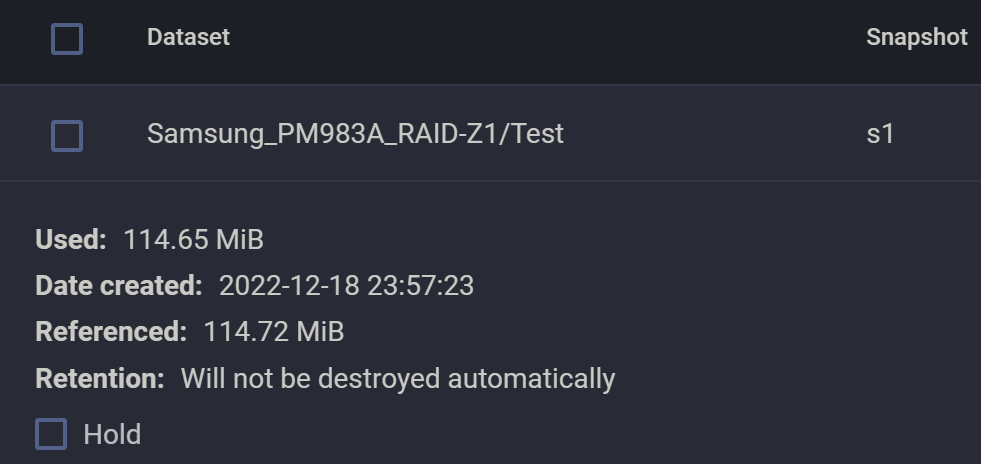
但是这里很诡异!Abbyy 删除一半页面并保存之后,快照变得和原先的文件一样大!再来看一下 dataset 的占用:

竟然由 115MiB 增加到了 170MiB. 所以,Abbyy 应该的操作应该是把旧文件直接删了,然后创建了新文件。所以旧文件被快照保留下来,成为快照的 Used 空间,新文件被写入新 blocks,导致 dataset 空间占用变多。
现在,我们回滚到快照 s1,并换一个 PDF 编辑器试试。这次我们选择 Adobe Acrobat Pro DC,做同样的编辑操作。查看编辑后的文件大小:
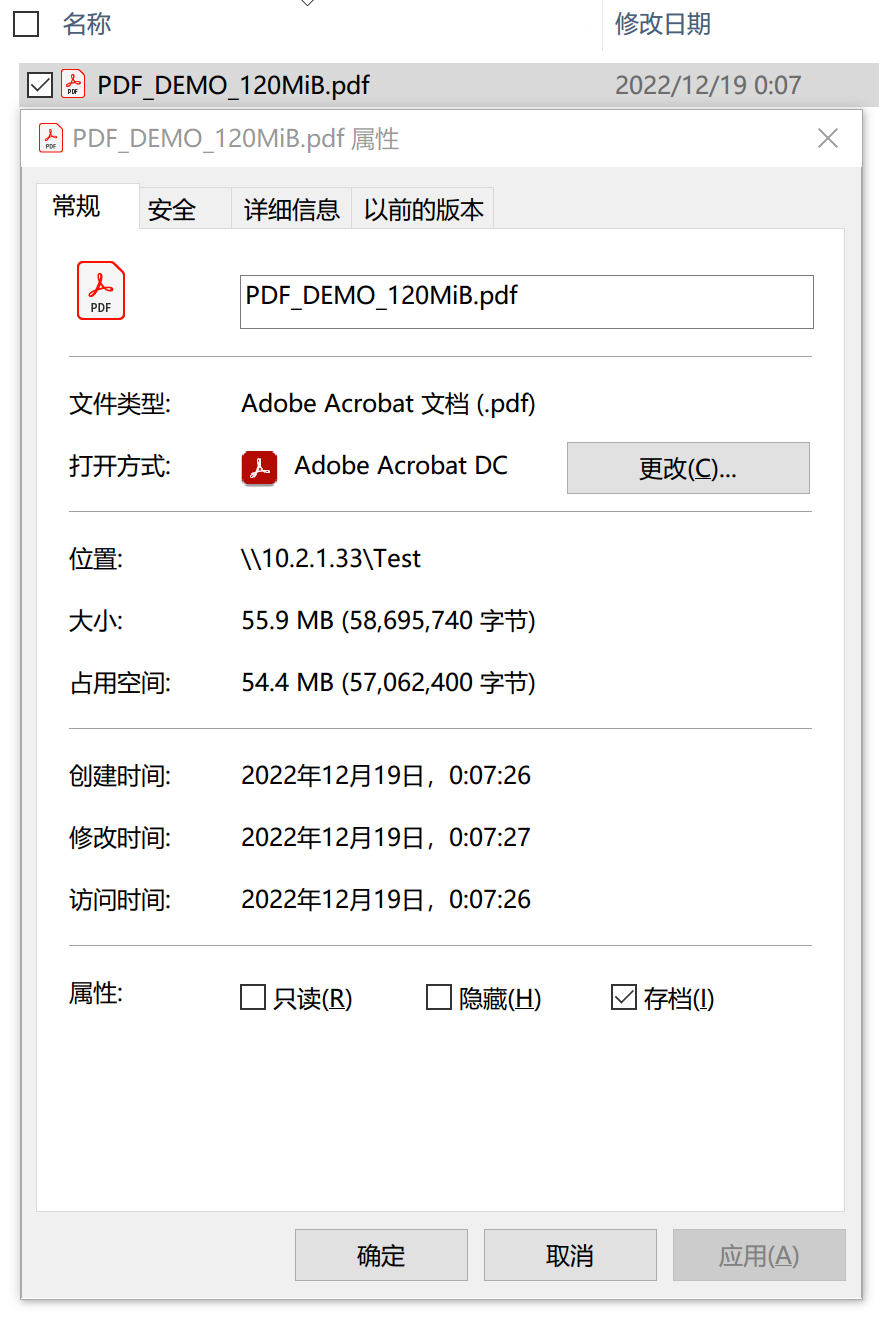
文件的大小变化符合预期。再查看一下 dataset 和快照 s1:

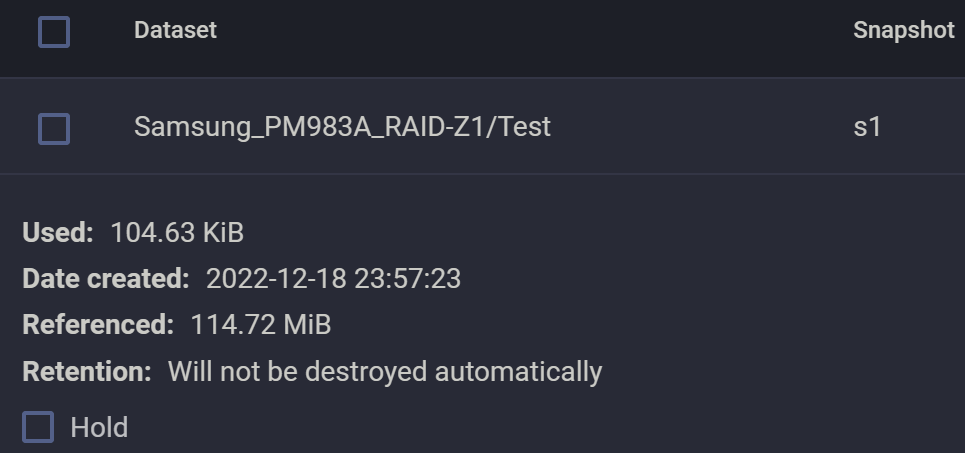
我们发现,快照并没有明显变大,但是 dataset 的占用和 Abbyy 是一致的,均增大到了约 170MiB. 在此基础上我们创建快照 s2,然后再把这个文件删除二分之一页面(相当于只剩下最开始文件的四分之一)。
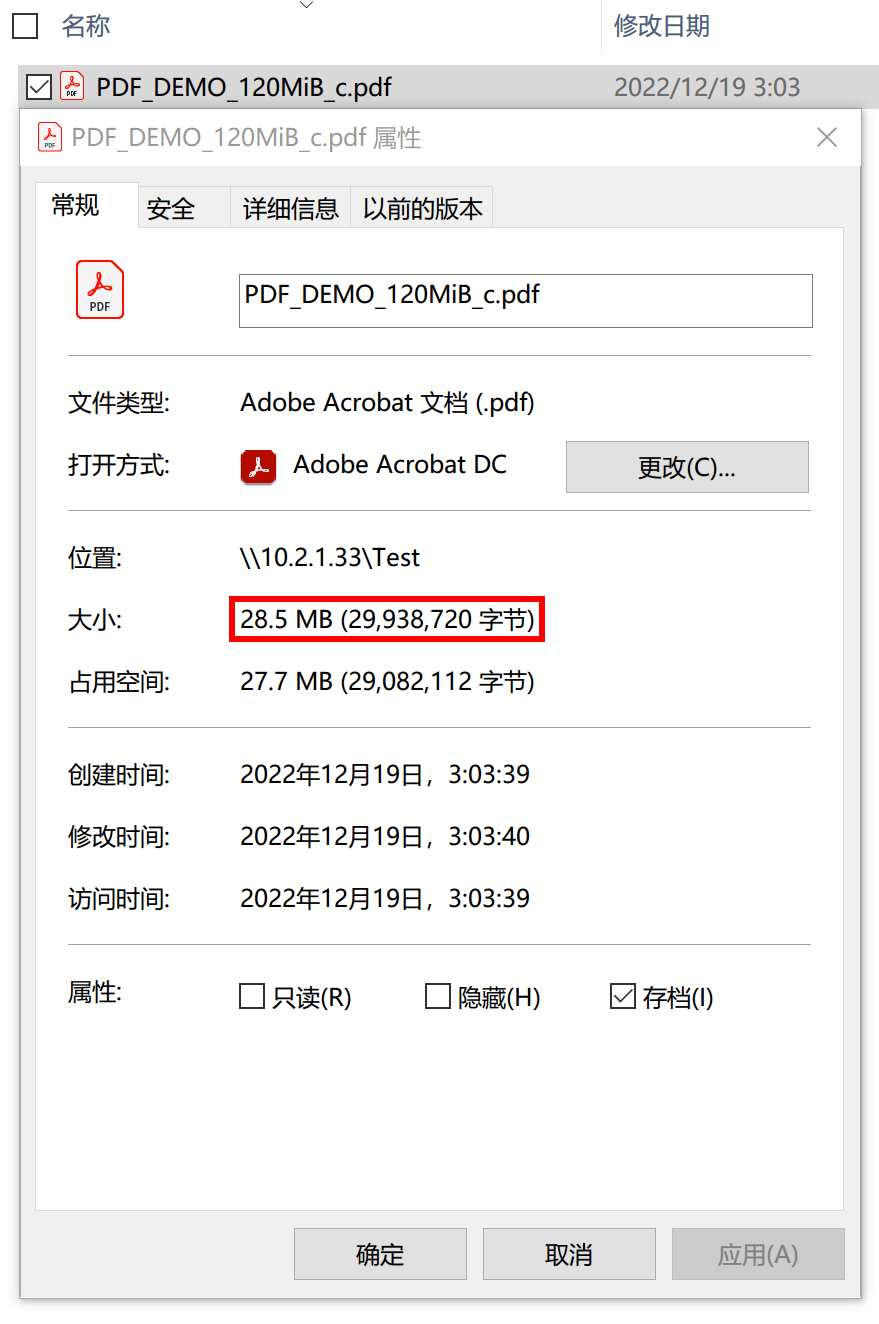
观察发现文件体积再度缩减二分之一,符合预期。同时,删除完之后发现快照 s2 也基本没变。
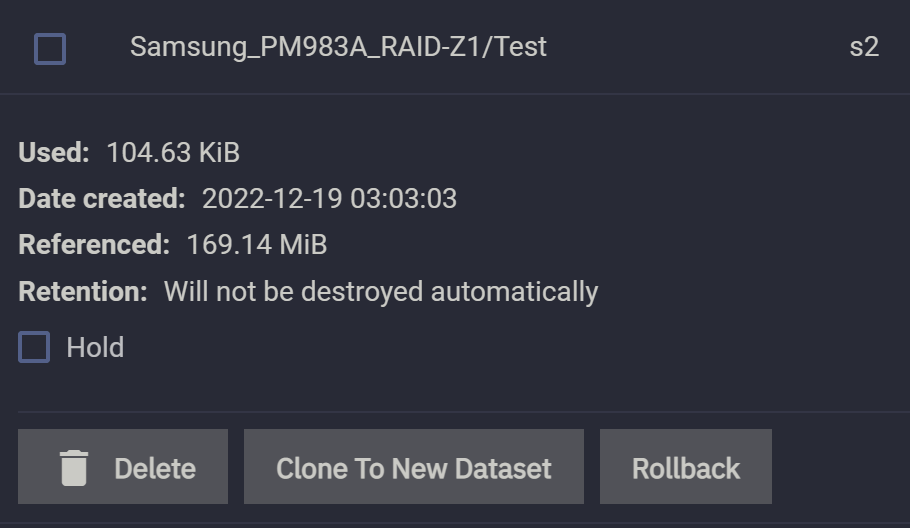
如无意外,dataset 占用应该增加 25MiB 左右。果然:

看来 PDF 编辑器对 PDF 文件的编辑不像我们想的那么简单,因此可得出结论:通过编辑文件的频率、细节推测快照占用、dataset 空间占用是不现实的,必须具体情况具体分析。
2.3.2 Copy-on-write 使得磁盘的 block 占用变得不可简单预期·
当你删除了所有的文件,可能发现 dataset 的占用还是挺大,比如我们经过上面一番操作,dataset 空了,也没有任何快照。但是系统依旧显示存在115MiB 的占用,这正是我们最初写入的那个 PDF 文件的大小。当然,这与系统的各种服务有关系,比如显示 115MiB 而不是 0 是因为我针对这个 dataset 开启了 SMB 共享服务,系统认为这个 dataset 还存在服务依赖,因此不能提前进入打扫阶段。当我们关闭相关 SMB 共享之后,空间将立马归零,读者可以自行查看。
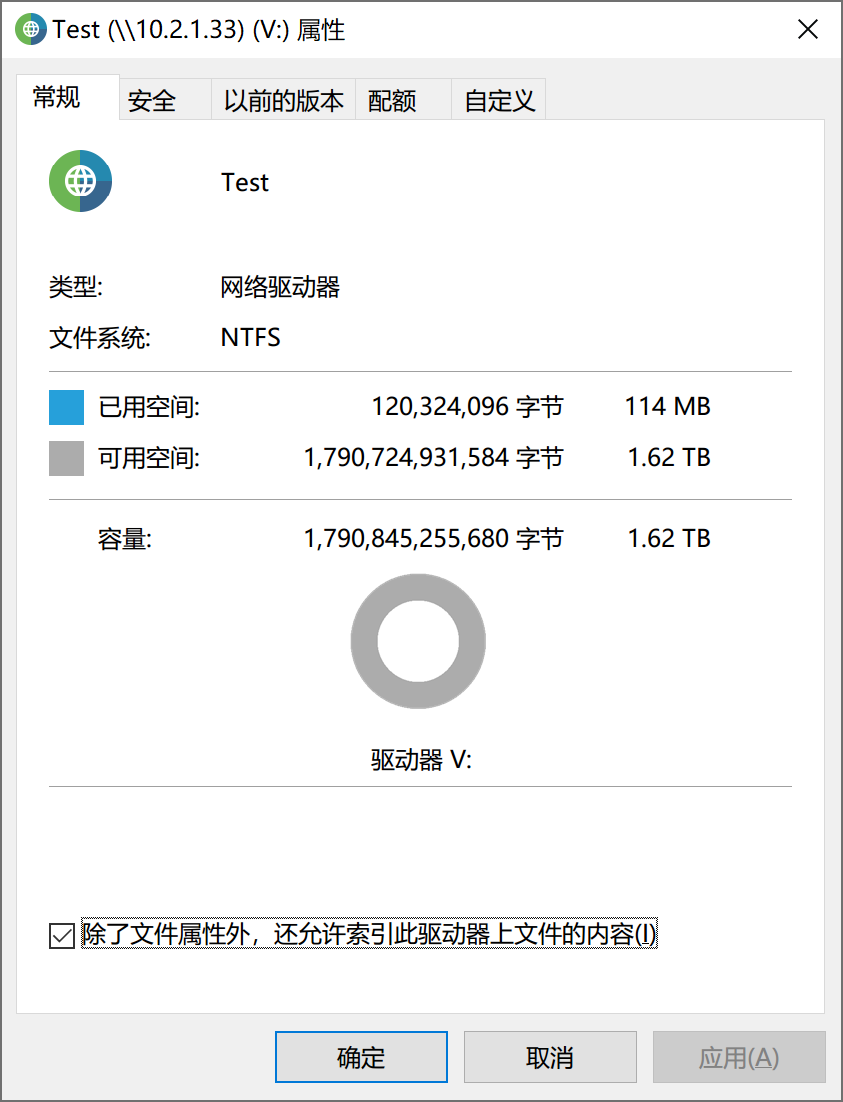

所以,copy-on-write 带来了很良好的快照功能,但是也造成了一些资源占用。处于 on-delete 队列的资源,可能需要在某些算法的控制下决定是否出队(比如是否存在相关服务依赖),因此对于全闪存来说,copy-on-write 有可能导致阵列提前进入满盘、脏盘状态。
2.3.3 zfs-diff 命令·
最后我们指出,可以通过下面的命令查看一下当前 zfs dataset 和快照 s1 的差异:
1 | # zfs diff 命令很有用,可以查看 dataset 的差异,就像 git 那样 |

on_delete_queue,在等待删除的队列里。通过查看我们发现,新加了一个名为 PDF_DEMO_120MiB.pdf 的文件,它与我们之前的文件同名。有一个同样名为 PDF_DEMO_120MiB.pdf 的文件被 Rename 重命名为 PDF_DEMO_120MiB.pdf(on_delete_queue). 目录 Test 被修改。
| ZFS 提示符 | 对应英文 | 含义 |
|---|---|---|
R |
Rename | 对比中,后面的那个dataset/snapshot对这个内容做了重命名 |
M |
Modify | 对比中,后面的那个dataset/snapshot对这个内容进行了修改 |
+ |
Add | 对比中,后面的那个dataset/snapshot中增加了这个内容 |
- |
Remove | 对比中,后面的那个dataset/snapshot中移除了这个内容 |
1 | $ sudo zfs diff Samsung_PM983A_RAID-Z1/Test@**s1** Samsung_PM983A_RAID-Z1/Test@**s2** |
2.4 快照容量计算:以虚拟机为例·
虚拟机的磁盘会被 hypervisor 存储为底层文件系统上的一个虚拟磁盘文件,比如常见的 qcow2、vmdk、vhdx 等。这种文件通常体积较大,而且更新频繁。这里通过 VMware Workstation Pro 17 进行测例。
首先举个生物信息学的例子帮助理解。针对 DNA 序列(三个相邻的含氮碱基构成一个密码子,一个密码子对应一种氨基酸),我们可以对某个密码子中的碱基对进行修改,这不会造成 DNA 信息的大规模丢失。但是如果我们在两个相邻碱基之间插入了一个新碱基,那么就会导致接下来的所有序列都重新分组,在 DNA 看来,自己的含义就全变了。在计算机存储中一般不会出现这种问题。
为了理解,我们以 VMware Workstation Pro 17 虚拟机使用为例。这里是一个简单场景:虚拟机开机,更新系统,然后关机。系统更新时,pacman 包管理器提示大概下载 1GiB 文件,安装展开 4GiB 多一点。理论上,在不考虑 ZFS 对 VMDK 的 block 进行 LZ4 压缩的情况下,虚拟机的文件系统快照应该会增加 5GiB 左右。
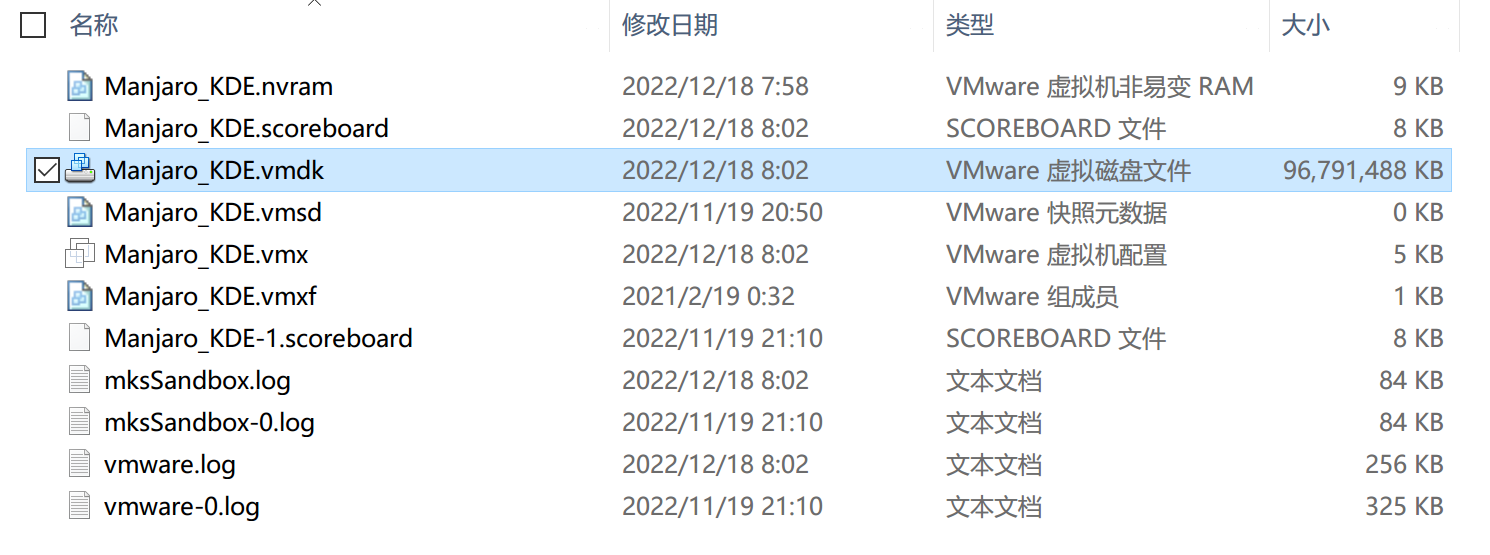
经过查验,发现仅增长了 4GiB 不到的空间。这验证了我们的猜测。
虚拟机的虚拟磁盘文件一般具有良好的空间局部性,不会因为修改一点东西就导致整个文件的大部分 block 都随之更改,因此对这种文件进行 ZFS 快照控制代价较低。
2.5 快照使用陷阱:不要在文件处于被打开状态创建快照·
ZFS 快照生成是具有原子性的(Atomic),但是它也是 block 级别的。越低级的东西就越彻底,但是也会不太合乎人性。比如你打开了一个文件,并且正在进行修改后的上传,在文件传了一半、还没调用 fclose 函数时,你打了个 snapshot,那么 snapshot 并不知道与 file 状态相关的信息。所以,你这个快照就只包含了“半个”文件,这个快照 rollback 回滚之后,你的该文件是不完整的,因为写入的管道不存在了。这种文件多了的话,就造成系统不稳定,依赖存储的计算程序也有可能出错。
强烈建议,在快照之前,确保文件写入均已完成,确保文件没有处于打开的状态!特别是在开了异步写的时候。
2.6 快照回滚:像 git 那样理解 ZFS·
比如依次打了快照 s1、s2,那么原则上要就近回滚:先回滚 s2,最后 s1,如果直接回滚 s1,会提示错误:
1 | [EFAULT] Failed to rollback snapshot: |
3. ZFS 存储迁移与备份·
小时候我就在想一个问题:如何才能让一个东西永远保存下去?长大后我发现,把信息这种东西永久保存的方法就是复制无限多份并存放在宇宙中不同的地方。因此,备份是保证数据可靠的唯一手段。所谓的各种 RAID,也是在更细的力度上用冗余的方式实现了较为可靠的存储。
3.1 ZFS 的快照特性:快照本身与数据具有同一性·
ZFS 的快照与 ZFS 的数据是存储在同一个介质上的,这一点非常显然。有些人可能不理解,还能有其他分离式存储?没错,有的。某些存储系统可以把快照存储在单独的磁盘上。
3.2 如何快速迁移、备份数据集?·
数据集里存放文件,同样,ZVol 也是存放文件。如何快速将一个 dataset 迁移呢?举个应用的例子,我现在有一个较小的 pool_A,里面有个名为 myData 的 dataset. 现在我想对 pool_A 扩容,但是我又不想通过加 vdev 的方式在线扩容,因此只能考虑把 myData 备份出来,格掉 pool_A 后加硬盘重新创建 pool. 虽然代价颇大,但这是较为彻底的手段之一。这个场景非常普遍,但问题一般落在第一步:如何将现有数据迁移出来?假设我现在有另一个 pool_B 可以容得下这个数据集,那么我们可以在 pool_B 里创建一个临时 dataset,然后把 pool_A 的 myData 中的数据拷贝过来。但是这么一来会面临很多麻烦,比如复制命令要对所有文件来一遍,如果含有较多小文件则必然导致传输速率降低,而且频繁的数据校验也带来了很大的性能开销。那么有没有快捷的方式做到这一点呢?有的,答案就是 zfs send | zfs recv 命令集合。
1 | # 以 root 模式运行这些命令 |
通过 Linux 管道,可以轻松将数据集进行复制。zfs-send 命令会将 dataset 读出为一个输出流,zfs-revc 会接受一个 dataset 流,并写入到一个新的 dataset 中。这个过程高度自动化、低级化,不会对文件进行操作,只是对存储块进行操作,因此效率非常高!
熟悉 Unix 内核的进程间通信的同学对管道应该很熟,zfs-send 确实可以将 dataset 的某个 snapshot 读出为一个输出流,至于你要对这个流做什么,那就和普通的流一样别无二致。你甚至可以将它保存为一个文件,然后将文件拷贝到 Windows 电脑上保存。灵活性非常高。
3.3 增量式使用 zfs-send·
增量传输在文件备份、同步里是相当重要的概念。修改了一个大文件,传输时仅传修改的那些文件块,这属于增量传输。若干个文件中,只有少数发生了修改,此时传输修改的部分文件也是增量传输。从这里可以看出,增量传输是一种思想,有不同粒度的实现。前者属于 block 级别,后者属于文件级别。目前市场上做得比较好的 block 级传输的是坚果云、Dropbox.
zfs 的快照备份也需要增量,因为我们很有可能是这样使用备份机器的:机器 A 配备了高速 SSD,用来进行日常使用,机器 B 配备了大容量机械磁盘,用来进行数据备份;每周五晚上,管理员将把机器 A 的数据备份到机器 B. 由于备份具有时间连续性,因此我们只需要备份本周内产生的差异性文件即可。zfs-send 命令天生支持增量备份,具体是通过指定 -i 参数和两个具有前后关系的快照实现的,命令行如下:
1 | zfs send -i tank1/dataset@s1 tank1/dataset@s2 | zfs recv tank2/dataset |
3.4 ZFS 数据集备份实战·
下面的示例非常简单:有两个 pool,第一个是 Intel 750 SSD 1.2TB x4 in raid-z1(下称 Intel),另一个是 Samsung PM981A 900GB x4 in raid-z1(下称 Samsung),源数据集在 Intel 里,备份的数据集在 Samsung 里。

接下来展示对备份做了修改会产生什么错误。
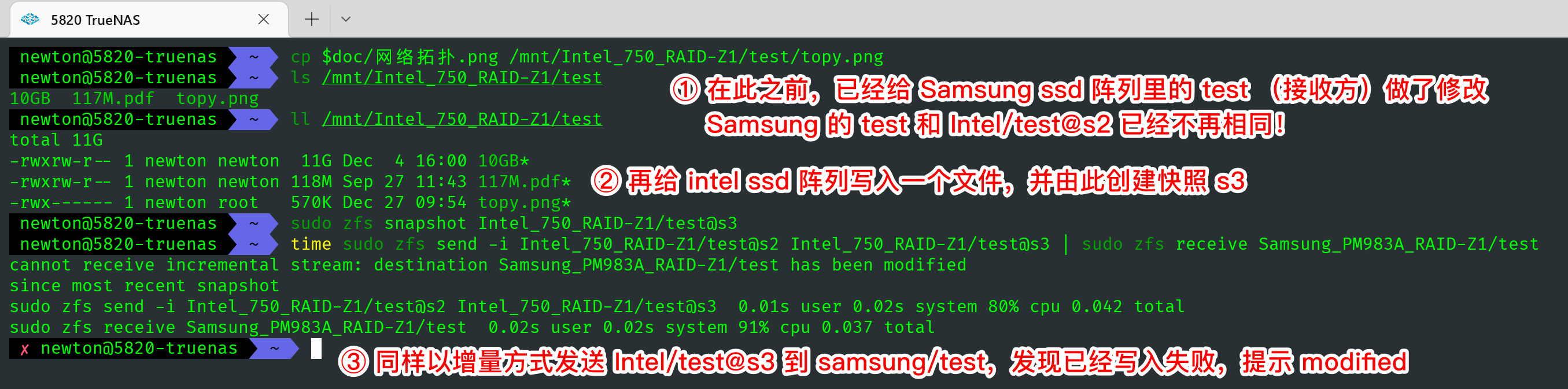
最后展示将流重定向到文件。此举有助于灵活备份。

1 | # zfs-recv,使用 -F 参数自动回滚到可增量状态。谨慎使用。 |
4. 权限控制之 ACL:NFSv4 vs POSIX·
ACL(Access Control List)是权限控制领域的一套思想。访问控制是信息安全领域经久不衰的话题,目前普遍认为 ACL 的出现解决了这个领域里大多数的问题。因此存储服务器的管理员有必要对 ACL 有深入的理解。
ACL 既然是个 List,就必然有一些表项,表项叫做 Access Control Entries,简称 ACE. 一个 ACE 就是某个文件/目录的 ACL 里的一个条目。
4.1 Linux 基础·
Linux 的用户在系统看来就是一个 ID,与你的用户名字符串没什么关系。Linux 的用户级访问控制是通过 ID 进行的,因此在 NFS 共享(跨系统)时,往往因为同名用户的 ID 不同导致权限应用失败。
对与存储管理员来说,初次创建用户,要考虑到用户在其他计算型服务器上的用户 ID. 保持 ID 一致是最完美的,否则还要设置 NFS 的 usermap,相对不太优雅。
1 | [参考] |
相比较 NFSv4,POSIX ACL 功能要弱一些。因此全文将以 NFSv4 为例子进行讲解。
NFSv4 类型的 ACL 用自带的getfacl和setfacl命令是无法操作的。必须使用 TrueNAS 自带的 nfs4xdr_getfacl 和 nfs4xdr_setfacl 命令,而且输出更加漂亮,能自动对齐。
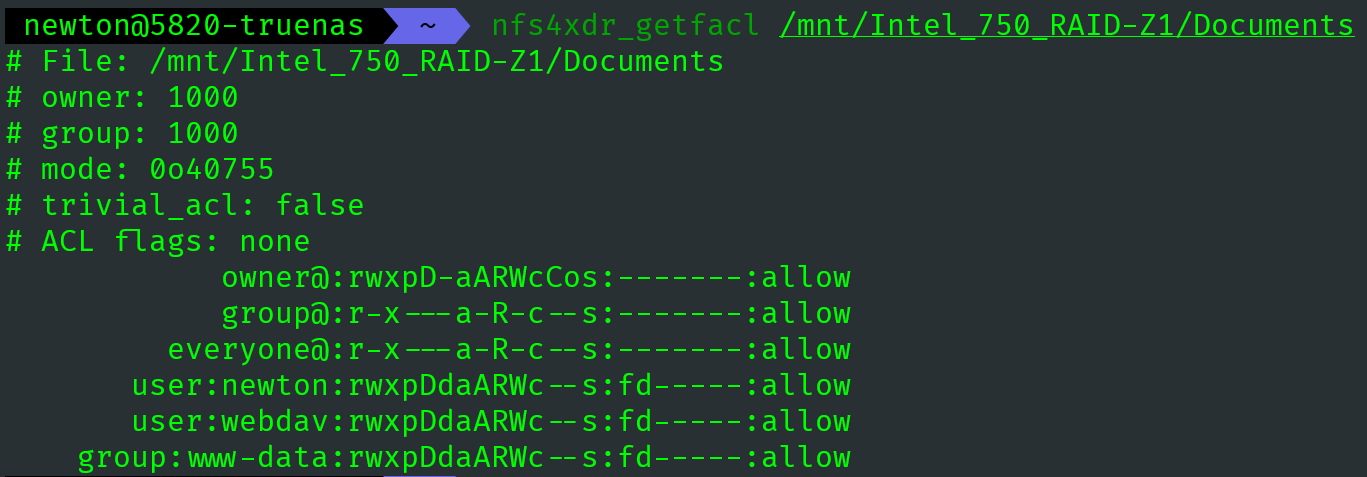
1 | # 查看帮助 |
4.2 NFSv4 ACL 权限细分及缩写·
1 | r read-data (files) / list-directory (directories) 读文件 / 列出目录里的文件 |
理解 NFSv4 ACL 很简单,配置命令也不难。常用 -a 添加 ACE、-e 编辑器里编辑、-x 删除 ACE.ß
4.3 NFSv4 权限简单缩写·
full_set,all permissions sets,所有 NFSv4 ACL 权限modify_set,all possible permissions exceptwrite_acl(C) andwrite_owner(o). 改写 ACL 和更改文件或目录持有人之外的所有权限write_set, all write permissions (wpAW). 所有与写相关的权限read_set, all read permissions (raRc). 所有与读相关的权限
4.4 ACL 实战·
通过 for 循环,可以对文件进行批量授权,防止不被认可的用户使用文件。
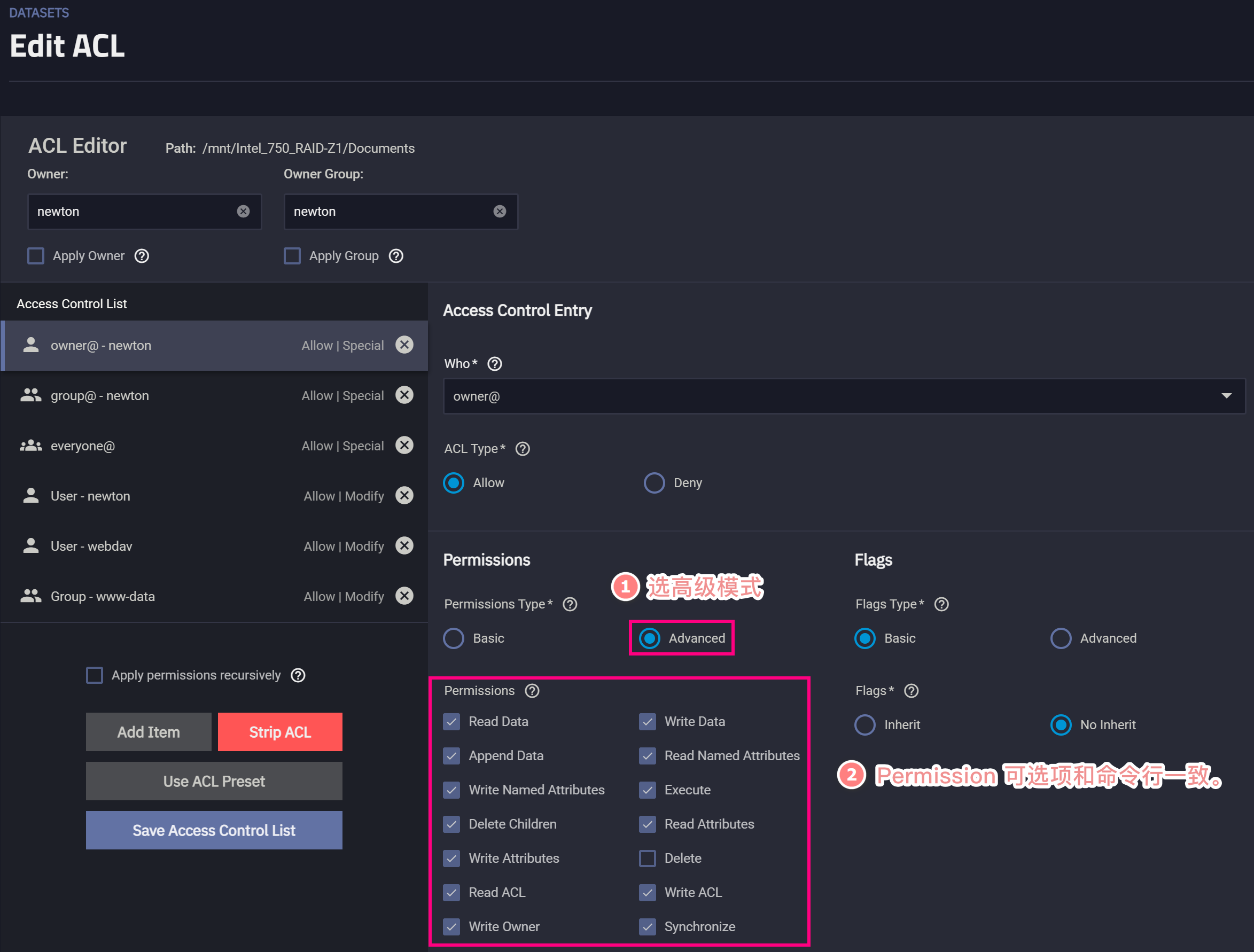
请务必明确一个事实:ACL 实现复杂的权限控制是通过对一个文件/目录施加多个 ACE 来实现的。反映在 TrueNAS 里,就是要对同一个数据集或文件添加多个 ACL Item(其实就是 ACE)。
4.4.1 如何实现普通用户对数据集可读、可创建文件、可创建文件夹、不可删除文件、不可删除文件夹·
这个需求相对比较常规,特别是在团队里,我们一般会允许某些员工可以读取数据,但是不能删除数据、删除目录。这么做一般是防止员工权限过大删库跑路,造成巨大的数字资产损失。
这里我们要添加两条 ACE,第一条是拒绝式的,拒绝用户对 dataset 删除文件、删除子目录。第二条是允许式的,即允许用户读文件、读目录、往文件里追加数据、创建目录、创建文件。我们通过 WebUI API 操作。
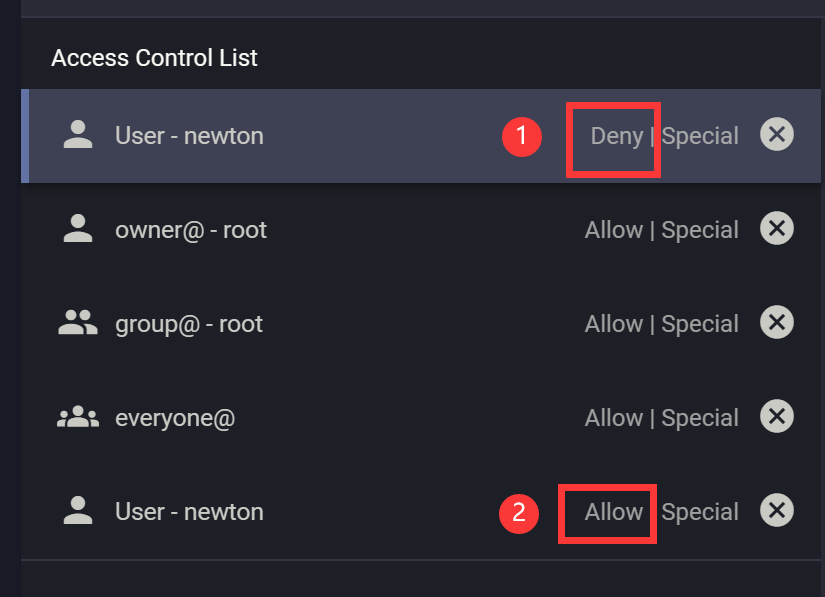
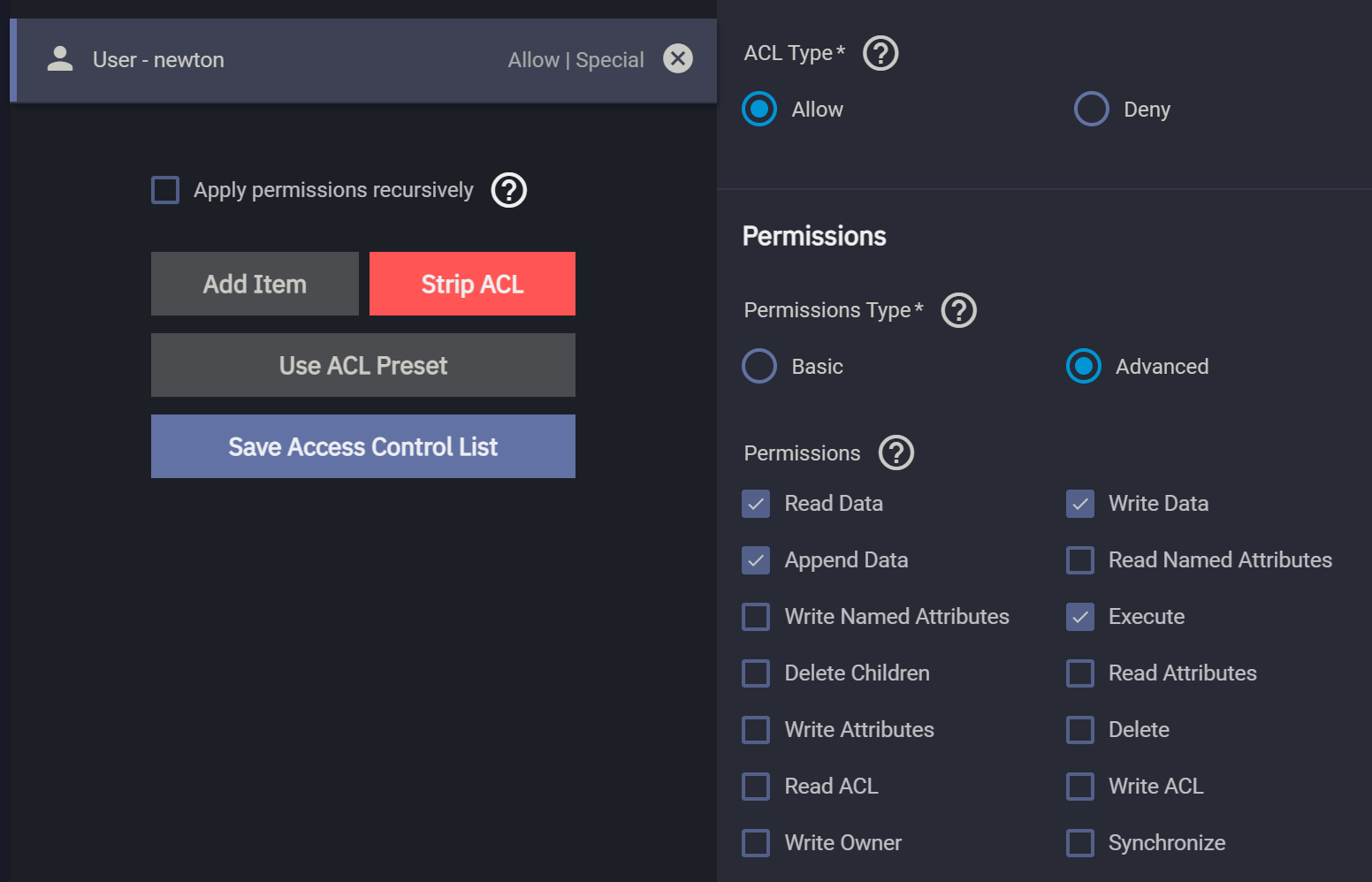
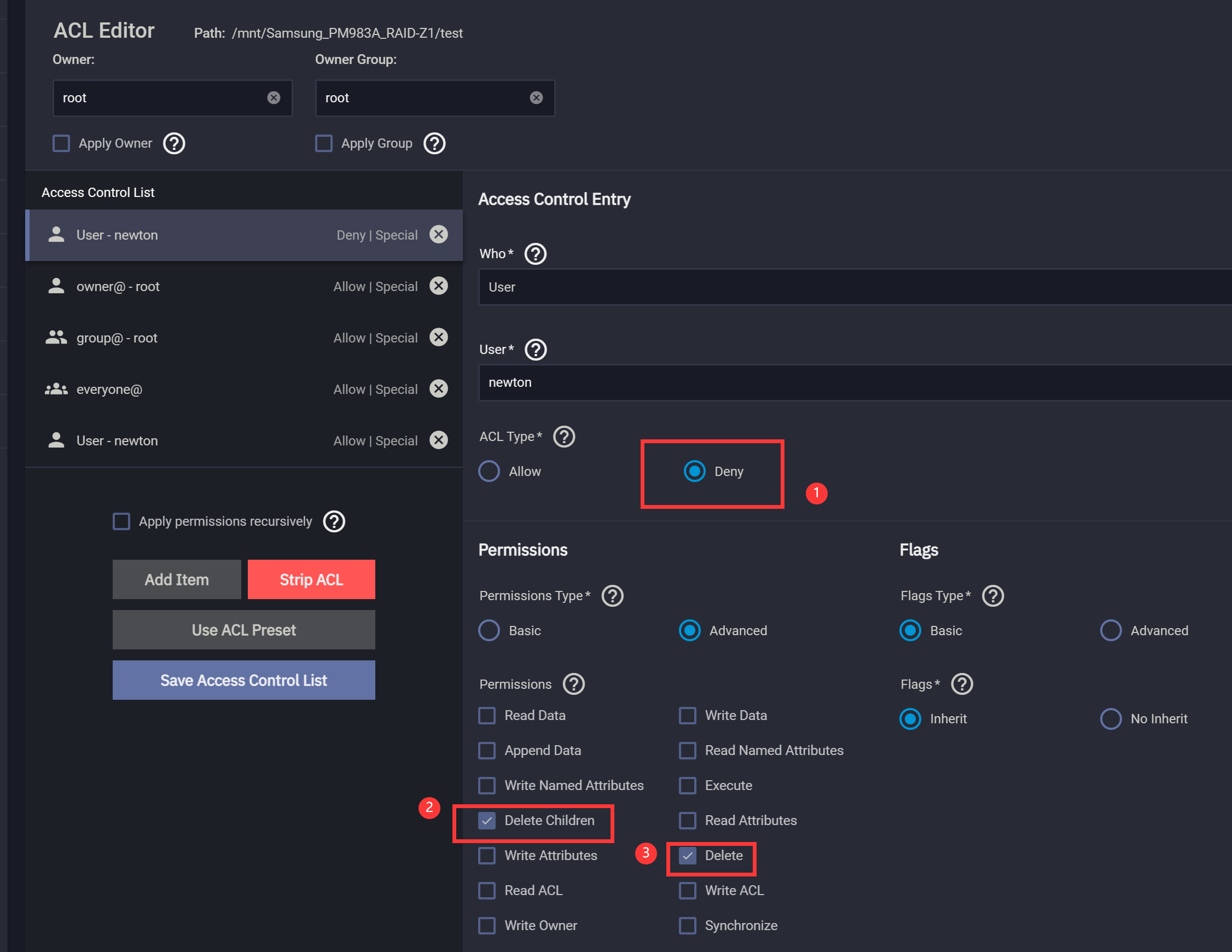
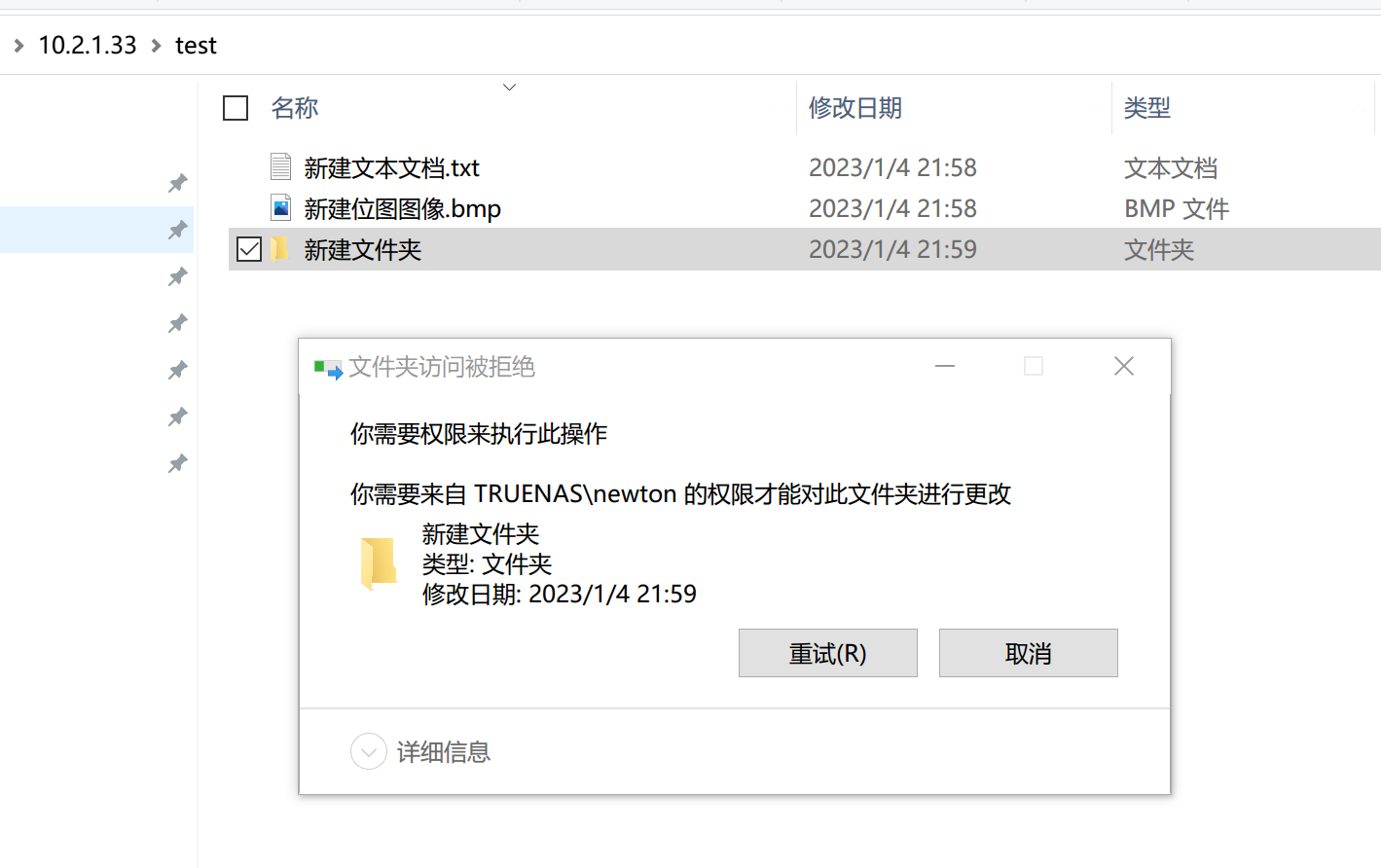
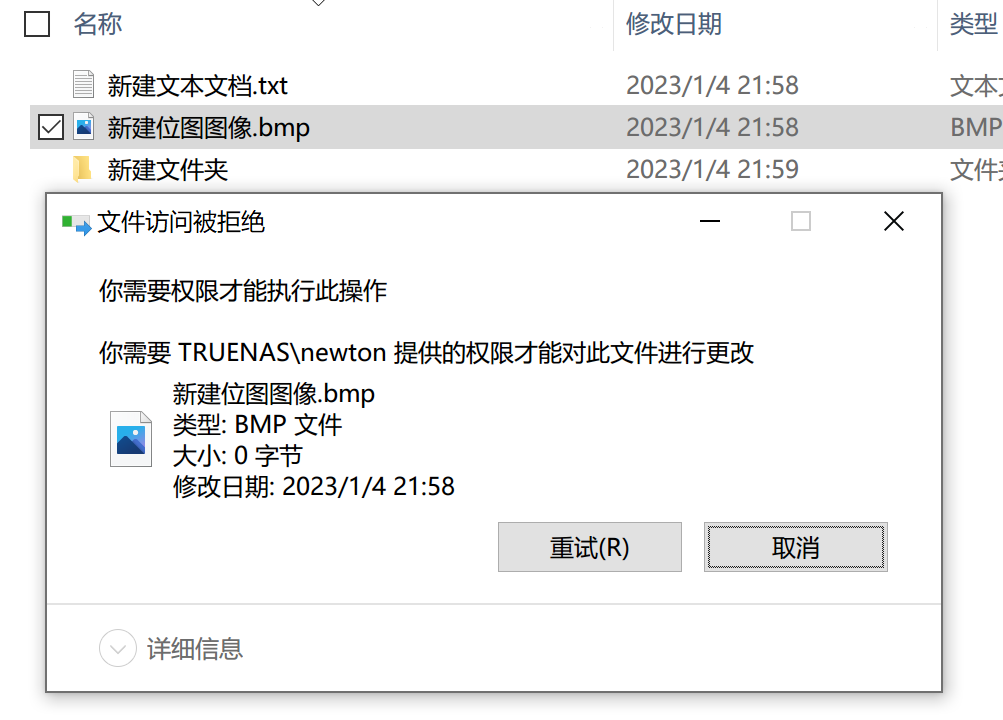
如此一来就可以实现 NFSv4 级别的访问控制。
5. OpenZFS 的内存使用·
1 | # 参考 |
FreeBSD 的 ZFS 是比较完善的,但是 OpenZFS 被移植到 Linux 之后就有一些水土不服的情况。比如在内存容量很大时,系统无法利用所有内存。ARC 的缓存策略非常复杂,arc.c 源码里对各个场景下 arc 的行为做了详细的描述。
5.1 手动设置最大 ARC 容量·
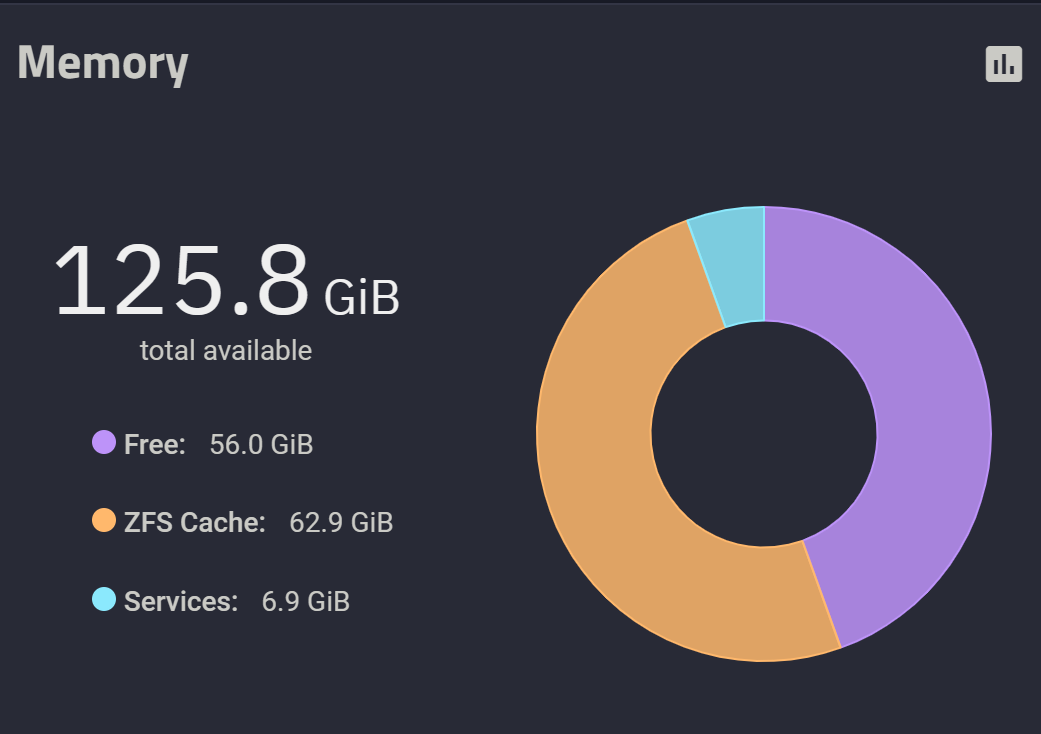
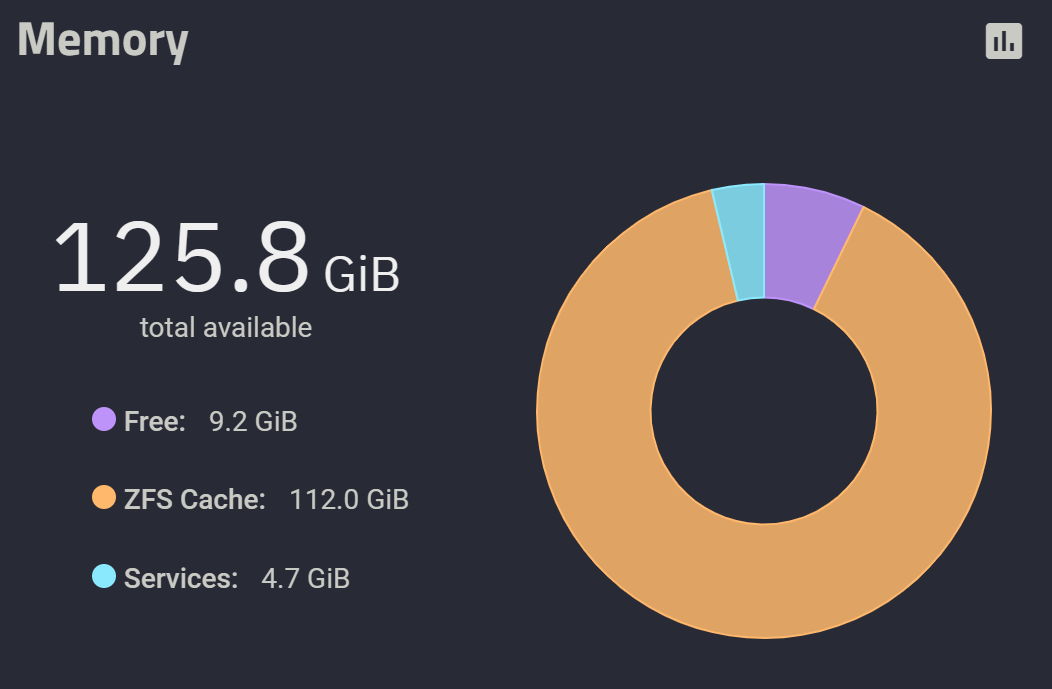
我个人不用 NAS 跑 docker,因此我把所有内存留给 ZFS cache 和服务 。
- 日常开启 iSCSI、SMB、NFS、SSH 服务,大概要吃掉
10GiB左右的内存 - 留
6GiB以作不时之需 - 给
112GiB空间做 cache
以上策略变更可以通过写系统数据实现:
1 | # 85899345920 = 80 * 1024 * 1024 * 1024 |
很多用户会强调使用 FreeBSD 版本的 ZFS. 诚然,FreeBSD 对 ZFS 的支持确实是最好的,然而 FreeBSD 内核却缺乏很多常见硬件的驱动,比如 Mellanox 万兆网卡。这导致存储的性能大打折扣!我建议在虚拟化场景下尽量使用 CORE 版本,在物理机场景下使用 SCALE 版本。
5.2 持久化 ARC 容量配置·
最后,为了避免重启失效,我们要持久化该配置。
1 | 在 WebUI 管理页面, |
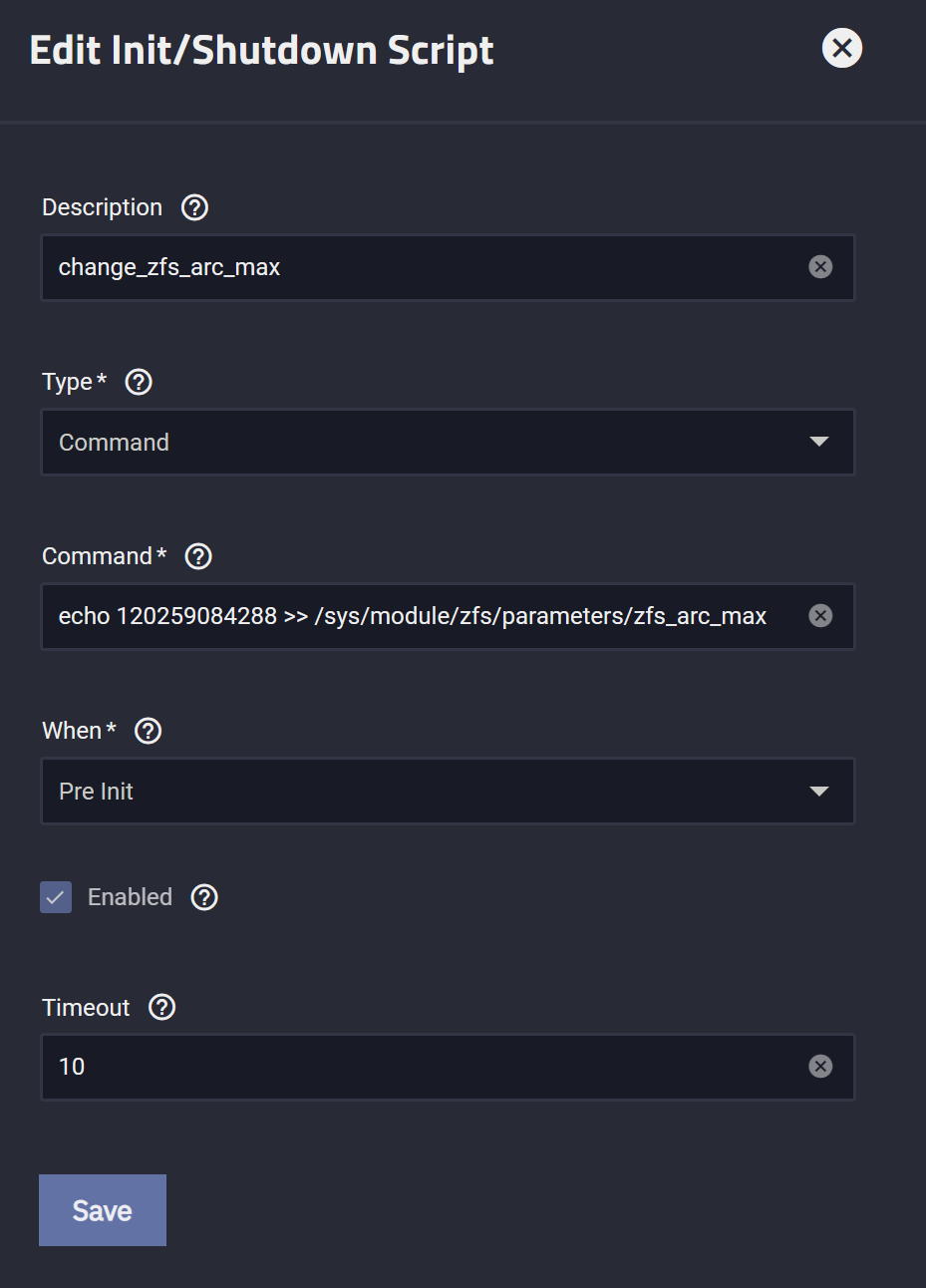
最后,不建议压榨太狠,至少要留 4GiB 空间给日常突发。
OpenZFS for Linux 的 ARC 部分还在继续完善,开发者的目标是设计并实现一种开箱即用的、对用户透明的动态 ARC 算法,目前来看,现实距离这个目标还很远,因此手动设置是有必要的。同样因为这个原因,我不建议在 NAS 上跑 docker,因为容器会给内存使用带来不确定性。