ZFS 存储教程 p1:卷管理
坑边闲话:笔者曾经一再强调,存储是计算机服务生命周期的最底层,一定要通过各种手段确保存储的安全,毕竟自古以来,从结绳记事到固态硬盘,其目的都是持久化地存储某些信息。ZFS 作为开源存储解决方案里的翘楚,得到了诸多玩家的青睐。然而,正确理解 ZFS 的诸多概念以及正确使用 ZFS 的特性,往往需要用户付出相当的学习时间。
1. 安全三原则·
一般来说,安全的系统至少要做到以下三点。
- 可用性。系统是可用的。为了防范黑客而关机、断网,就失去了可用性。
- 私密性。系统通信、存储的数据不被窃听、破解。HTTP、FTP 明文通信就不够安全。
- 完整性。通信、存储的信息不能被随机因素所改变,更不能被有心之人篡改!
- (不可抵赖性算第四原则吧)
可能你会觉得我在给大众普及安全常识,但是安全恰恰是所有上网的人都需要的。如果你的 NAS 被黑客黑了,那你再聪明也只能在一堆没有灵魂的硬件面前怀疑人生。所以本期内容看似是在讲存储,实际上是在讲安全。希望你能秉持着安全至上的原则看下去。
2. 常规存储服务器介绍·
首先介绍一下存储服务器。
现今的大企业一般标配存储服务器。PureStorage、NetApp、DELL EMC、H3C、Hewlett Packard Enterprise (HPE) 等企业级提供商也均有自己的当家产品。以 HPE 的 Alletra 9000 系列为例,它支持多个控制器,电源内置超大容量电池,哪怕在拔掉电源线后也能撑一段之间,直到缓存中的数据写入 non-volatile 的介质中。现代化的存储服务器一般集成多控制器以实现高可用,支持实时快照和 IOPS 的 QoS,针对不同的业务提供不同的 IOPS 性能。


2.1 存储可以防御勒索软件攻击·
下面简单说明几个虚拟化场景下骇客攻击的场景。
- 第一,黑客把你的虚拟机黑了。这个很好理解,因为虚拟机与宿主机有严谨的隔离,所以虚拟机内部的恶意程序一般不会从虚拟机中跑出来,最多也就是虚拟机业务挂了。但这并不意味虚拟机被黑代价很小,虚拟机可能负载一些关键业务,这种业务的停机会导致巨大损失。此外,有些人可能在 Windows 虚拟机里使用浏览器上网浏览,并在浏览器里面保存了一些历史记录、用户名和密码等,如果不凑巧你的 vCenter Web 密码也在里面,那么黑客就能大摇大摆地通过虚拟机控制你的物理机,甚至是控制你的带外管理界面。所以虚拟机安全也是不容忽视的,尽量不要在虚拟机里存储敏感数据,虚拟机浏览器的密码托管服务尽量关闭。
- 第二, Hypervisor 被黑了。这时候就很难办了,因为骇客能直接看到你的所有虚拟磁盘文件 (如 VMDK、VHDX、QCOW2 等),加密后勒索你就是分分钟的事。一旦 Hypervisor 被黑,那么你将直接凉凉,所有的虚拟机都完了。不过这种情况下,骇客也接触不到某些数据。比如你给虚拟机直通了硬盘,无论是 rdm 映射还是直通 NVMe、SAS 控制器等,骇客都没办法在 Hypervisor 上看到这些硬盘里的数据,因此在黑客无法破解虚拟机访问权限的情况下,直通硬盘里的数据是比较安全的。不过也不能掉以轻心,如果黑客拿到了 PVE、ESXi 的 web 权限,那么他就能通过 KVM 直接控制你的虚拟机,更改密码也是分分钟的事儿。只有更安全,没有最安全。
2.1.1 勒索软件的原理·
勒索软件控制你的方法很简单,那就是给你的重要数据加一把锁,只有付了钱他们才有可能给你解锁。这里我们不得不介绍一下内网存储服务器。
假如我们使用 ZFS 做存储底层,那么ZFS 是有数据完整性保护和即时快照功能的。我们可以通过 CIFS、NFS 等文件系统共享的方式,让虚拟机直接通过网络挂载 ZFS 里的某个共享文件夹,然后我们在 NAS 上定期创建快照,哪怕客户机被黑,CIFS、NFS 的数据被上锁也不怕,因为我们随时可以在存储服务器上回滚数据集。
- 假如你的虚拟机遭到攻击,虚拟机挂载的 CIFS、NFS 数据也被黑客加密,那么只要存储服务器还能正常工作,那你就可以在存储服务器上恢复快照,不影响关键数据。ZFS 支持创建 ZVol 逻辑卷且 ZVol 能通过 iSCSI 协议挂载,进而能被虚拟机识别为本地硬盘。ZVol 在 ZFS 系统上也能创建快照,也支持数据完整性校验。所以无论是虚拟机挂载还是 hypervisor 挂载存储服务器,它们均能借助 ZFS 快照功能实现数据恢复。当然,前提是你的 ZFS 存储服务器不能被黑掉!
- ZFS 的控制平面(也就是 web 管理、SSH 管理)一定要保护起来,尽量不接入外网!
- ZFS 服务器的 web/ssh 端口号改成不常用的,多次连接不通过就 ban 掉对方 IP 地址;
- 关闭 SSH 密码登录而采用公钥、证书登录;
- 即时更新 ZFS 存储服务器,一旦 OpenSSL 有更新一定要及时跟进,万一因 0day 漏洞被攻击,后果不堪设想!
3. ZFS 基础教程·
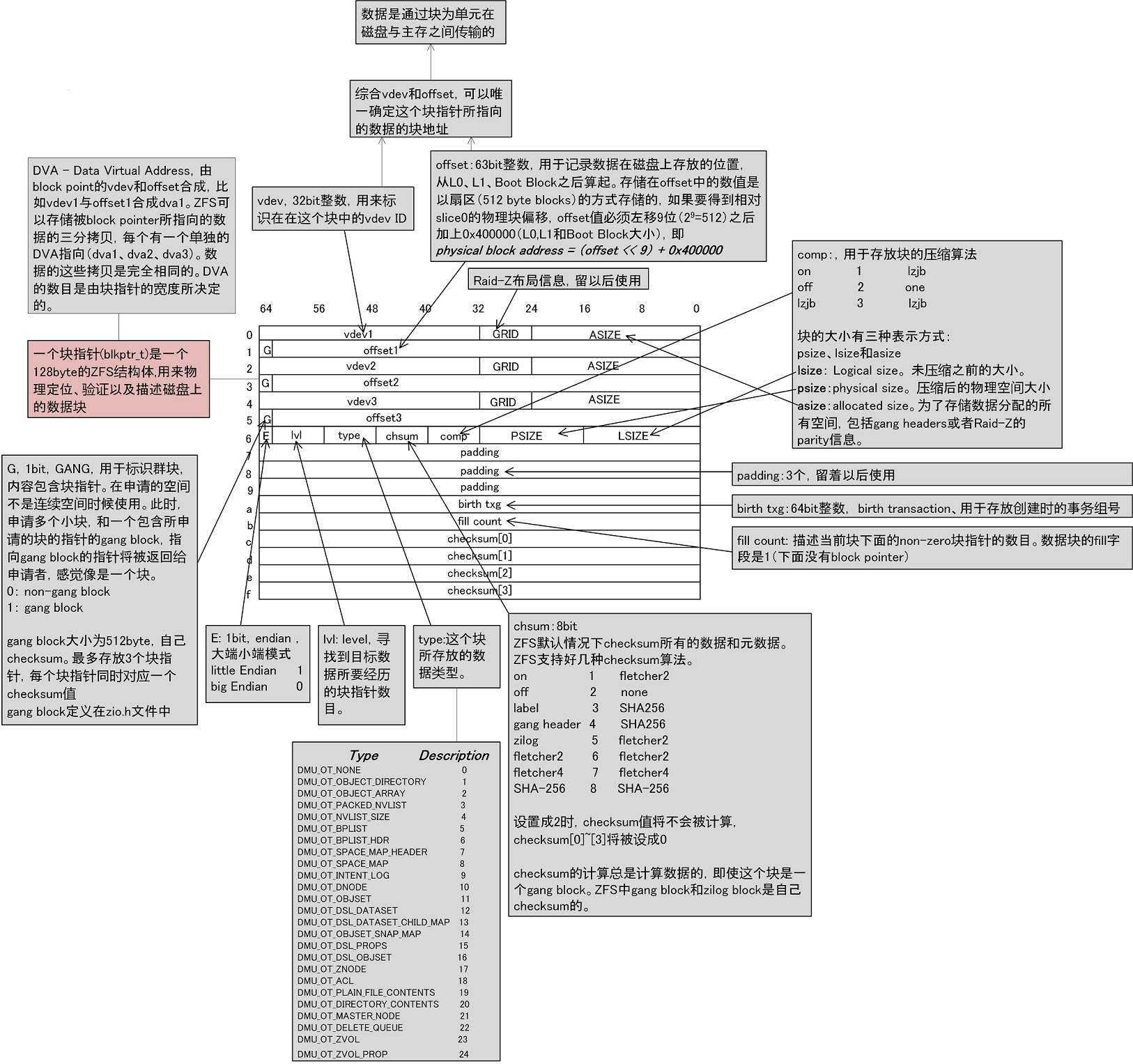
3.1 ZFS 块指针的结构·
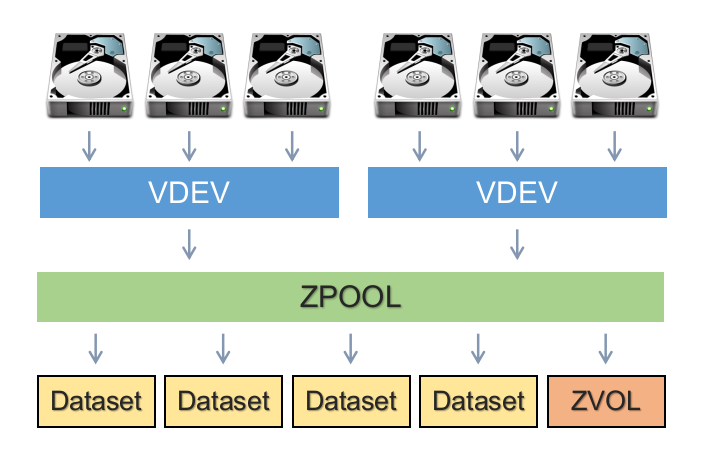
3.2 ZFS 的存储池布局·
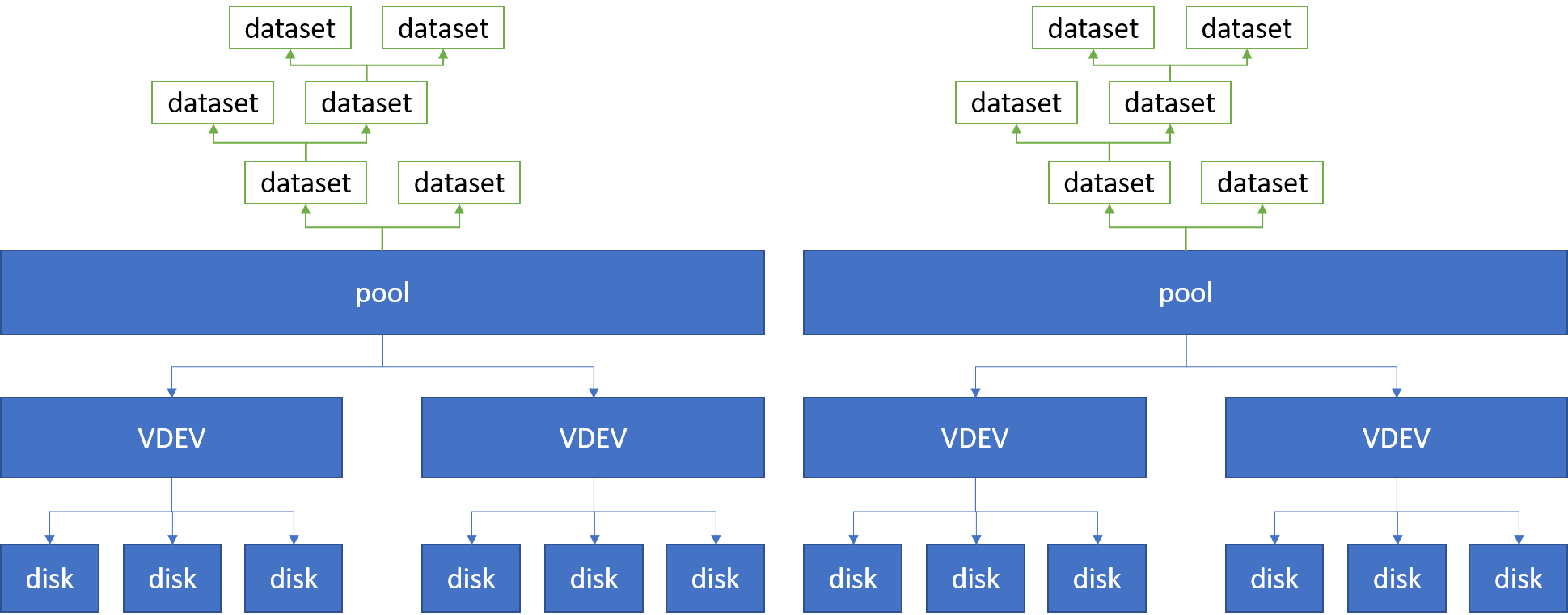
下面这张图能更好地体现 dataset 和 ZVol 之间的关系。
3.3 ZFS 扩容实战·
这里我们通过一个简单的实例来演示如何给 ZFS 的 pool 扩容。
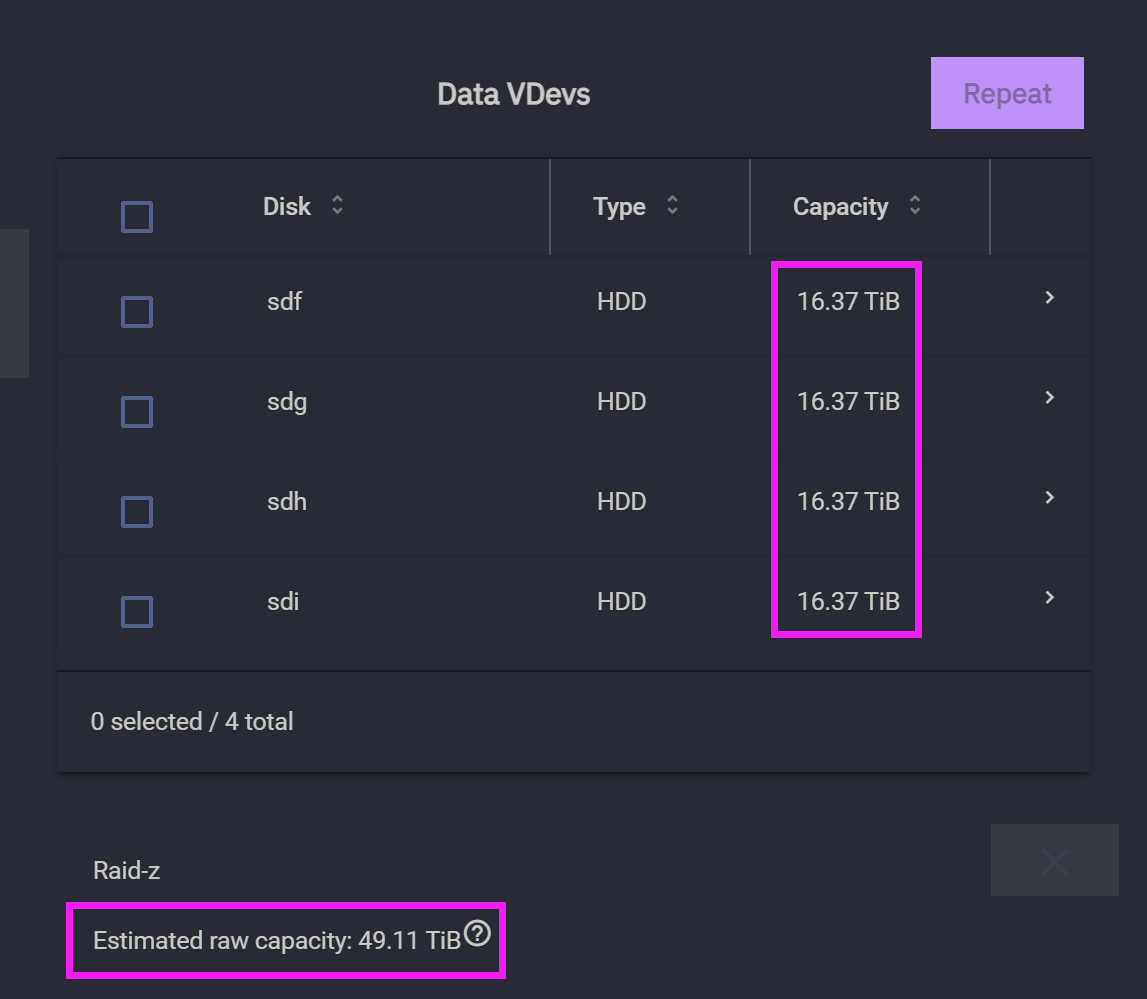
首先让我们想一下,如何给 Windows 扩容?答案很简单,那就是多增加一块硬盘。但是 ZFS 的扩容不是以单块硬盘为单位的,而是以 data vdev 为单位。比如一个 pool 的 data vdev 是四盘 RAID-Z1,那么你再往里面添加 vdev 时就只能再加一个四盘 RAID-Z1 的 vdev. 换言之,ZFS 扩容比较奢侈,必须一次性添加多块硬盘。当然,ZFS 也支持一块一块地添加,不过前提条件是你的现有格式是单盘 Stripe 做一个 vdev.
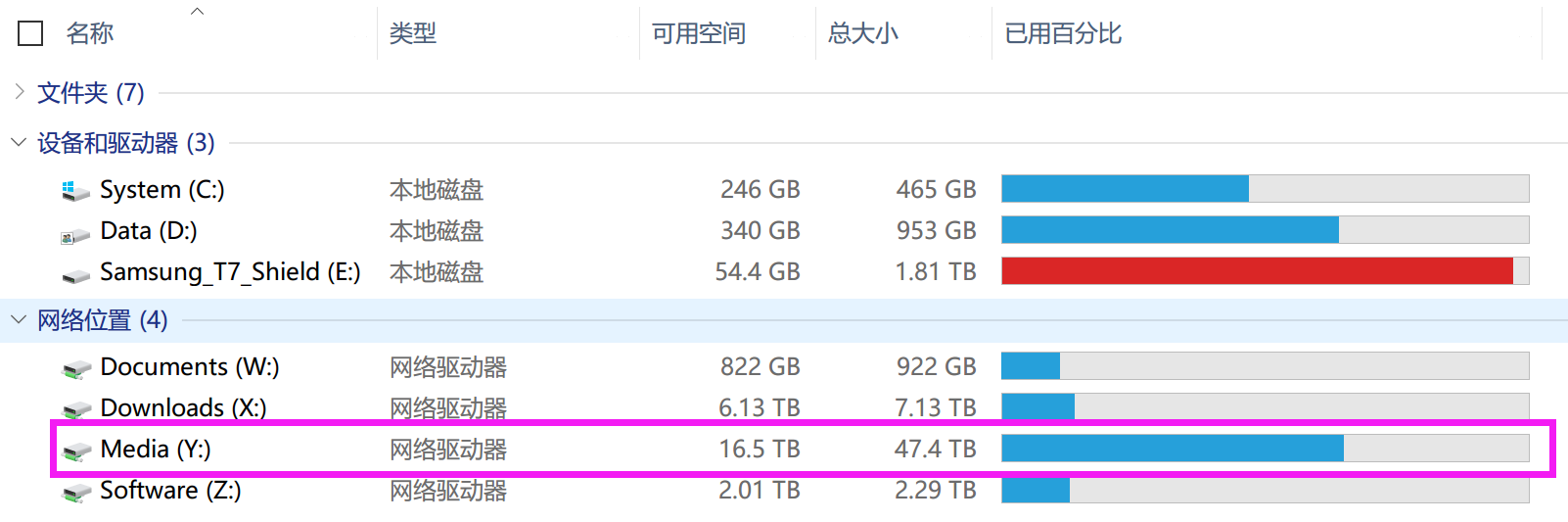
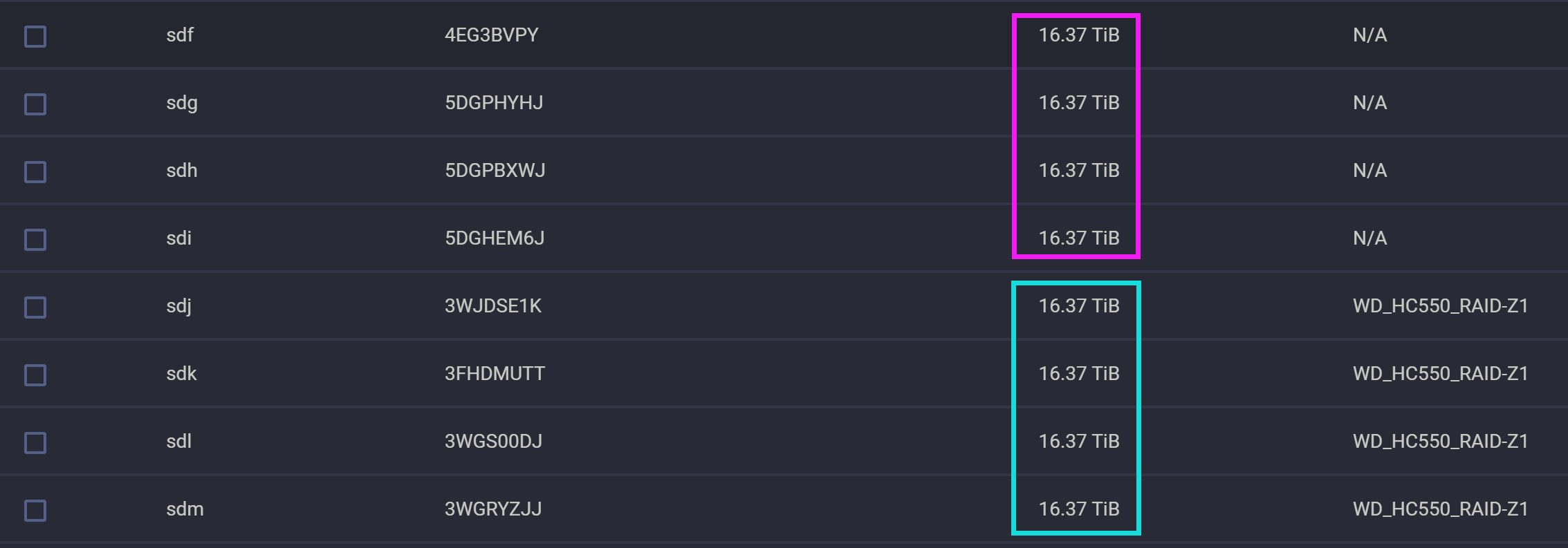
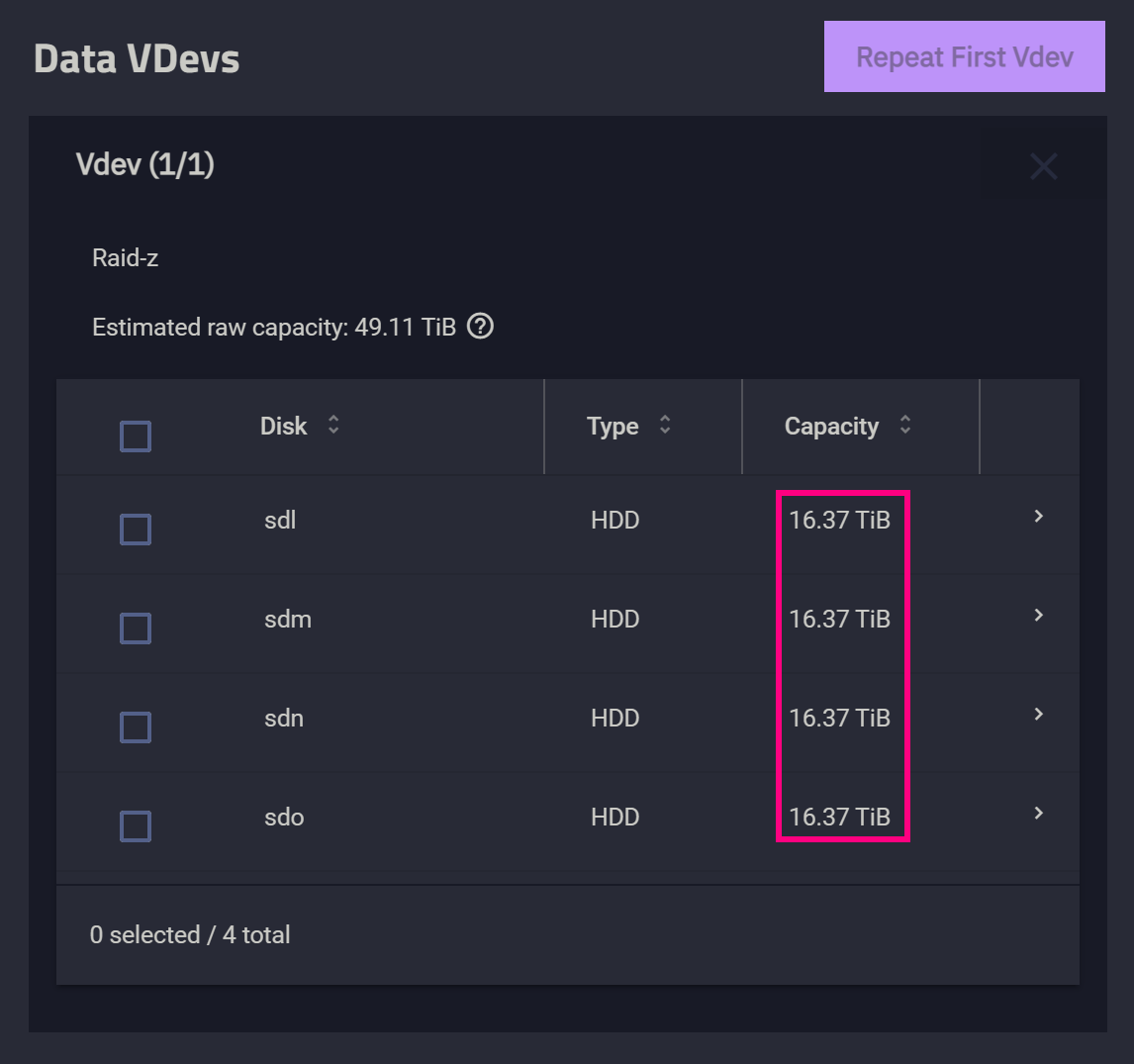
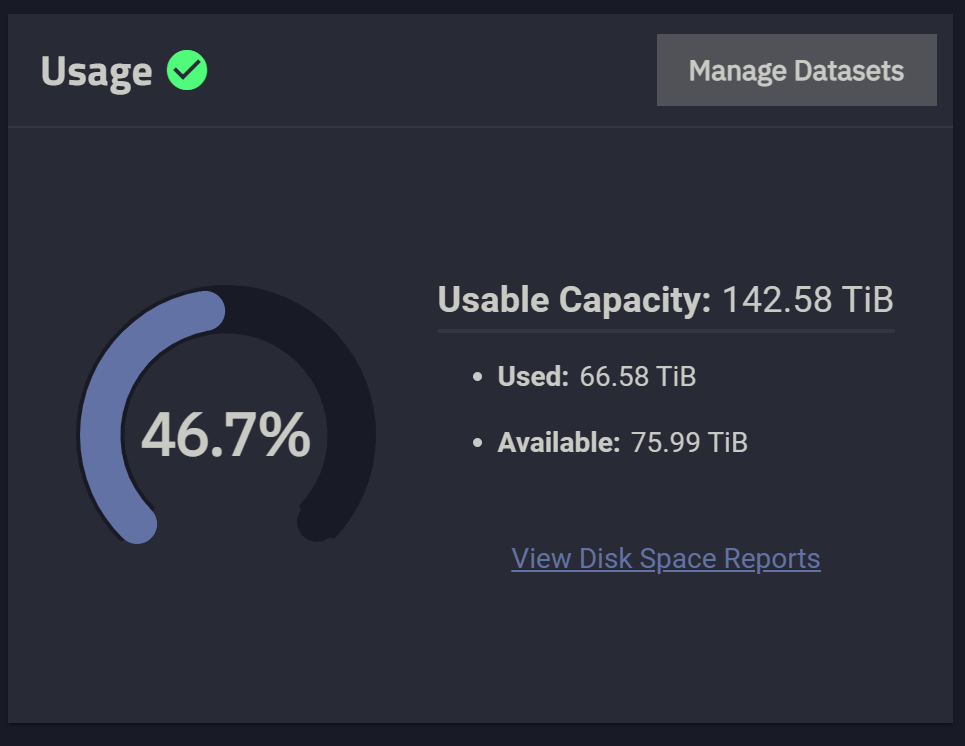
接下来我通过一个实例来演示如何给一个四盘 RAID-Z1 的 pool 扩容。首先看下图,Media 共享文件夹所在的 pool 大致有 47.4TB 的空间,它是由四个西部数据 HC550 18TB 组 RAID-Z1 构成的。


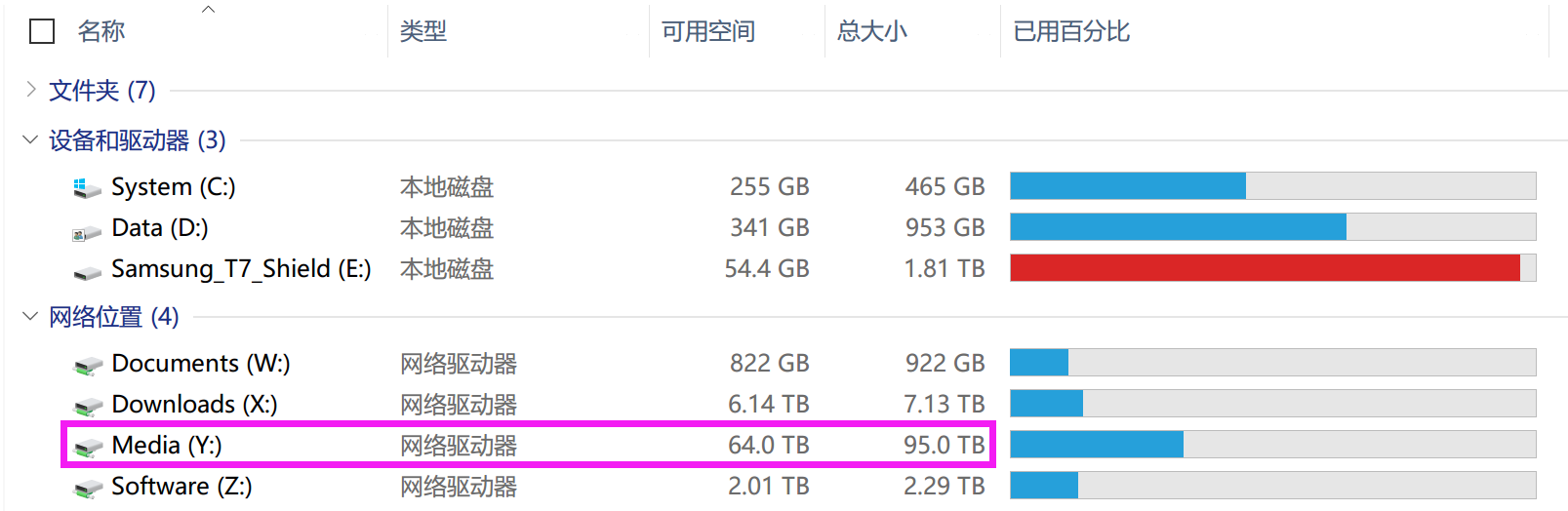
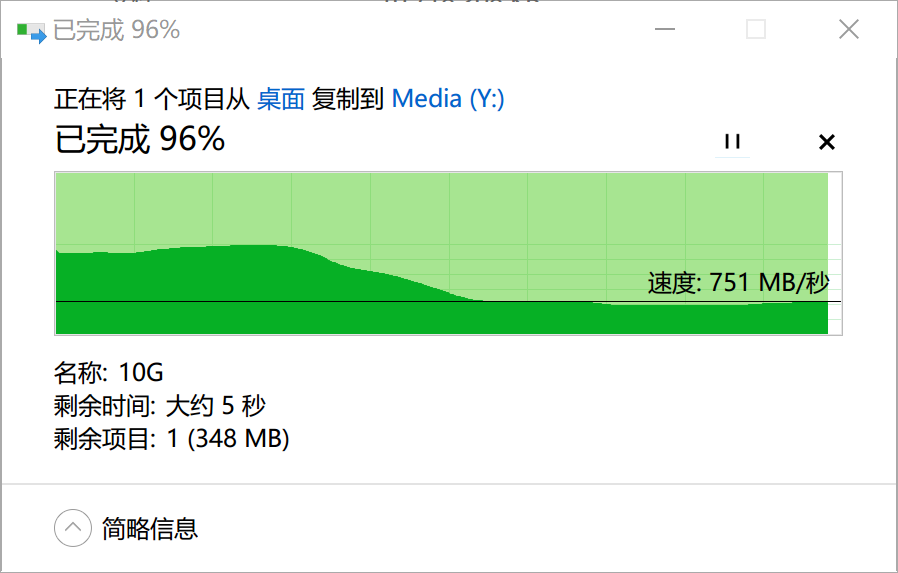
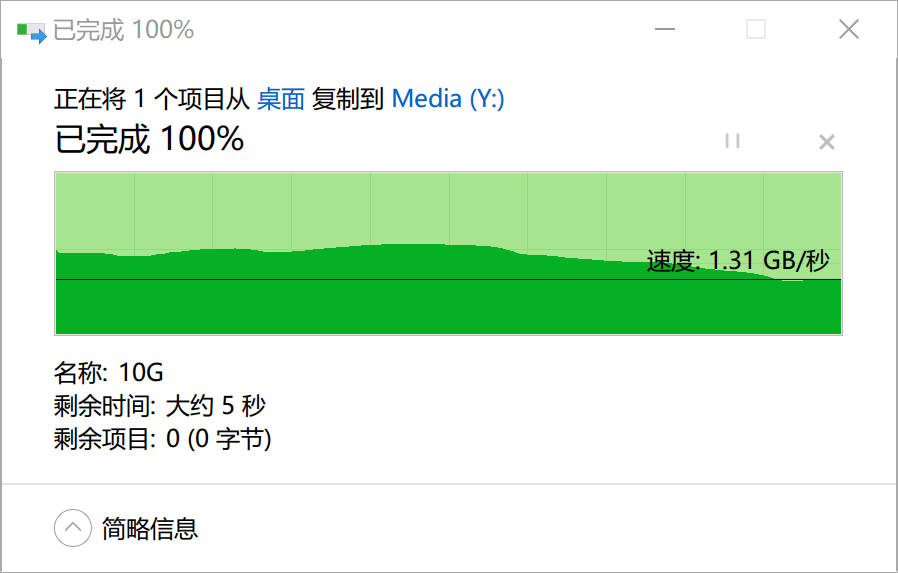
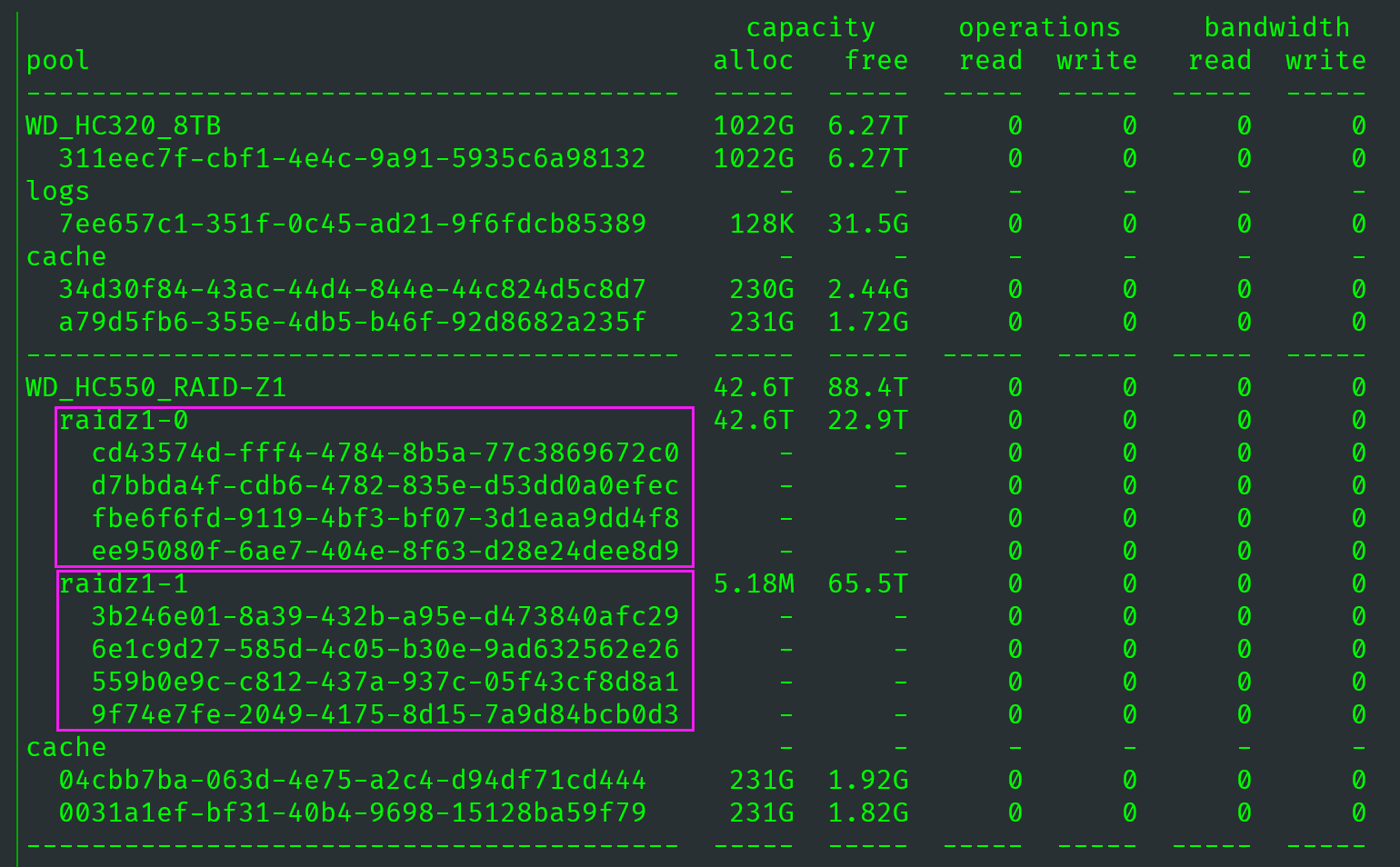
3.3.2 再次扩容·
通过观察同一阵列的再次扩容,可以让我们更深刻地理解扩容前后的变化。

随后创建新的 Data vdev 即可。
系统继续会提示警告。

OK,一切就绪。
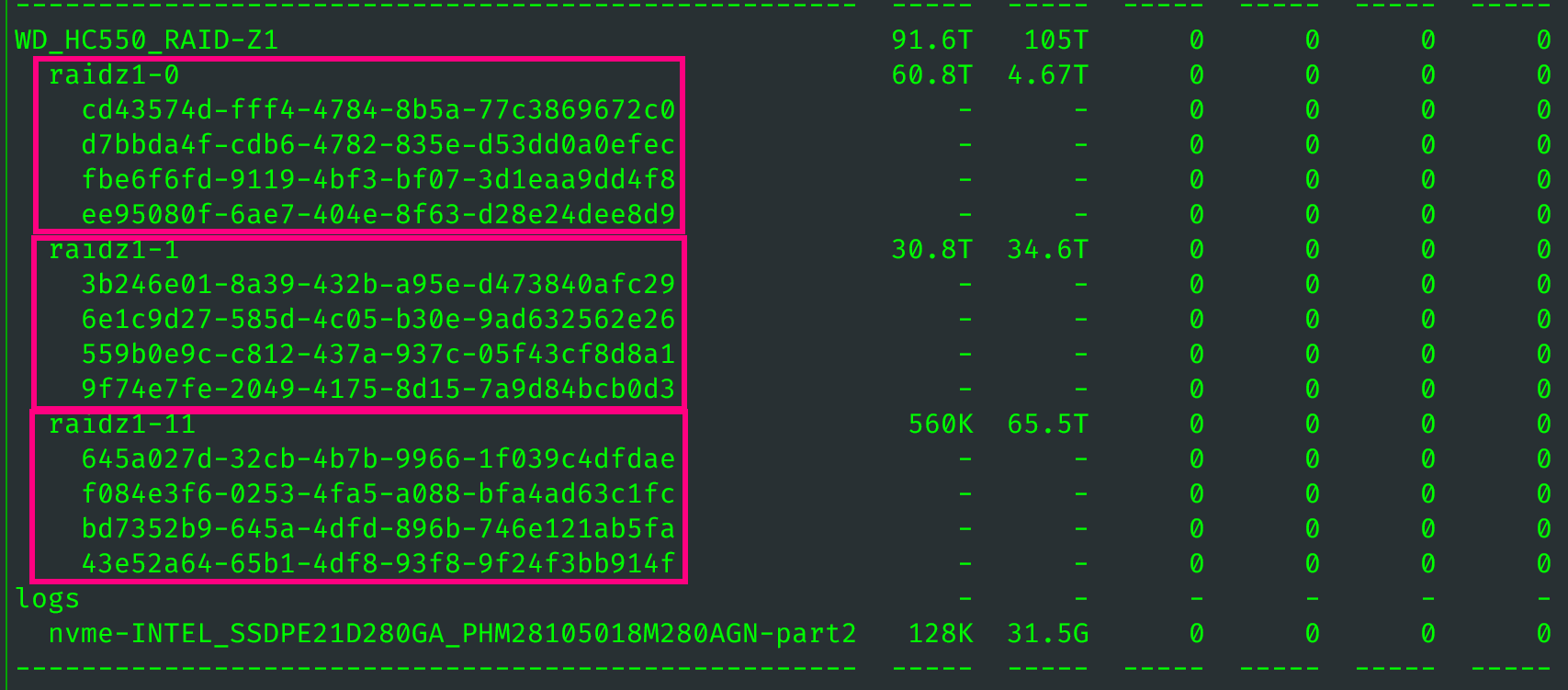
后来我又扩容了三次,产生的新 vdev 分别名为:
raidz1-15raidz1-16raidz1-17
真让人捉摸不透。
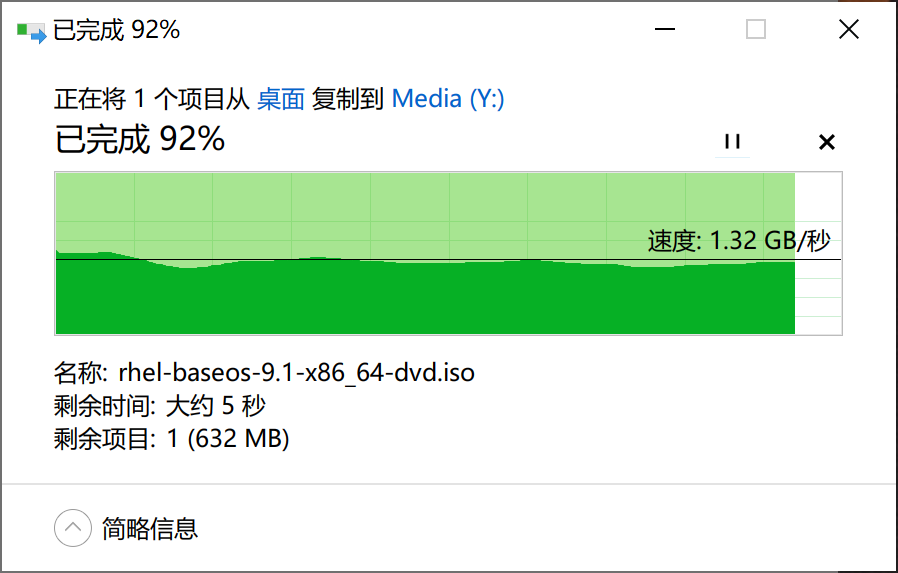
最后测试一下第二次扩容之后的速度。
3.4 ZFS 基础 Q&A·
Q&A 1. dataset 和文件夹有什么区别?·
答:dataset 类似于磁盘分区,可以手动设置该分区的 block size,也可以单独给这个 dataset 做快照。ZFS 容易给新手引起误导的地方就在这里,因为 TrueNAS 的文件系统默认在 /mnt/ 目录下,而 dataset 上建立的 dataset(下称子 dataset)形成的目录结构与子目录一模一样,所以很多人认为子 dataset 就是就是某种文件夹。这个理解大错特错。首先说明,两个 dataset 之间移动数据,并不能像文件夹里移动那样瞬间完成,哪怕两个 dataset 在一个 pool 里,移动数据也要从一个 dataset 里读出来,再写到另一个 dataset 中去,这个过程耗时是比较久的。如果没有特殊需求(包括但不限于快照、使用特殊的 Record-Size 等),个人建议还是用文件夹比较好。
Q&A 2. 我该选 ZVol 还是 dataset?·
虽然都是数据共享,但 ZVol 仅支持 iSCSI 协议做块共享(Block Share),而 dataset 更灵活,它能通过 smb、nfs、webdav 等协议实现多系统多用户同时共享(也称文件系统共享)。
两者的核心区别在于,ZVol 的文件系统在客户端上,dataset 的文件系统在 NAS 上,两者的原理完全不同。
要注意,iSCSI 连接 ZVol 是只能给一个客户端共享,并不能让多个客户端一起连接同一个 ZVol,因此多个用户共享电影、音乐、办公文件等场景,不宜用 ZVol. 而虚拟机扩容等场景,用 iSCSI 比较好。iSCSI 可以实现更低级的功能,而且在权限上更彻底。在 docker 场景下用 smb、nfs 等共享协议往往会遇到一些用户权限问题,一般人不容易搞明白。参见本节。
另外还要注意:
Q&A 3. 我有 8 个盘,组 raid-z2 还是两个两组 4 盘 raid-z1 呢?·
RAIDZ-1 和 RAIDZ-3 推荐使用奇数的磁盘,因为 1 和 3 是奇数,奇数减奇数就是偶数。RAIDZ-1 应该从 3 个开始,在阵列中不超过 7 个磁盘,而 RAIDZ-3 应该从 7 个开始,不超过 15 个。RAIDZ-2 应该使用偶数的磁盘,从 6 个磁盘开始,不超过 12 个。这是为了确保你有一个偶数的磁盘,数据被实际写入,并使阵列的性能最大化。
4. ZFS 中级教程·
4.1 什么是 Copy-on-Write?·
对机械硬盘而言,最小的存储单元是扇区(SSD 里也有类似的概念),同一位置的所有盘片的扇区构成一个柱面。现在的硬盘里大多有 2-9 个盘片,因此柱面的高度在 2-9 之间。磁盘读一次、写一次的最小单位是扇区。目前主流机械硬盘的扇区大小是 4KB.
对文件系统而言,最小读写的单元不是扇区,因为扇区太小了,逐个读取扇区会带来严重的性能下降。因此现代文件系统会把一串扇区综合起来,记录为一个区块。区块的大小是可变的。区块如果弄得太小,就会使得文件系统频繁向磁盘发送 I/O 请求。这在 ZFS 里反应非常明显,因为 ZFS 的校验值就是以区块为基本单位。同一个文件,切成 100 个大块与切成 1000 个小块,在读写的性能上有非常大的差距。
- 传统数据库文件系统建议用小块,如
8KB,16KB - 视频影音、备份压缩包等存储文件系统建议用大块,如
1MiB
4.2 ZFS 阵列恢复·
传统的 RAID 在恢复时,存在一些问题。假如 4 个 10T 的盘做了 RAID5,其中某个盘坏了,系统重建 RAID 时会重建 10T 空间。哪怕实际仅用了 2T,空闲的 8T 也会被傻瓜式校验一遍,因为这是个很低级的过程。在 ZFS 上,因为文件系统知道 RAID 模式,所以可以按需重建,只需要恢复 2T 的数据即可。
4.2.1 文件错误、校验和错误等导致阵列降级·
一般而言,个人建议每个月执行一次 Extended/Long 模式的磁盘 S.M.A.R.T 扫描,确定磁盘处于健康状态。
此外,每周进行一次数据 scrub(没找到很合适的翻译,我个人翻译为“盘点”),ZFS scrub data-set,保证数据确实良好地存储于文件系统上。
有时因为突然断电导致 ZFS 上某些文件产生了损坏,此时 ZFS 在盘点文件时发现有个文件发生了错误,ZFS 首先会尝试修复这个错误,比如从 mirror 的地方复制正确的数据过来。这个过程叫 self-healing,即自我修正。这个过程是静默且自动化的。但有时也有一些错误 ZFS 实在没法修正,此时常规的 RAID 可能会直接宣布阵列损毁。然而,ZFS 一般不会这么极端,如果错误不是很多,而且你检查完了硬盘的 smart 信息后发现磁盘硬件确实良好,那我个人认为可以忽略这种错误,特别是对于某些影音数据。日后在你删除某些有错误的文件之后(CKSUM),ZFS 可能就正常了。
1 | # 执行下面的命令可以清空错误 |
但是要注意,在你 zpool clear 之后,错误又出现了,而且重复几次 clear 都不管用,那么说明损坏的是当前的某些热数据,也有可能是磁盘、磁盘线真的坏了。可以尝试将当前使用的文件删除(如果可以的话)然后重新下载(生成),但是这个办法对一次性的珍贵文件不起作用。珍贵文件建议还是异地备份比较好。
4.2.2 磁盘产生坏道、坏块,要替换硬盘·
如果通过 smartctl 命令查看磁盘硬件信息后发现磁盘确实有问题,那么建议立即换新硬盘。如果有空闲的槽位就直接插入新硬盘,如果没有槽位可以找个 USB 硬盘盒将同型号的硬盘接入 TrueNAS. 但是一般的磁盘损毁不会导致磁盘完全不可用,因此没必要立即把坏掉的硬盘拔下来。可以采用热替换的方式替代坏盘。
raid-z 扩容也要遵循这个原则,不要急着拔硬盘。而是要采用热更新的方法逐个在线替换。
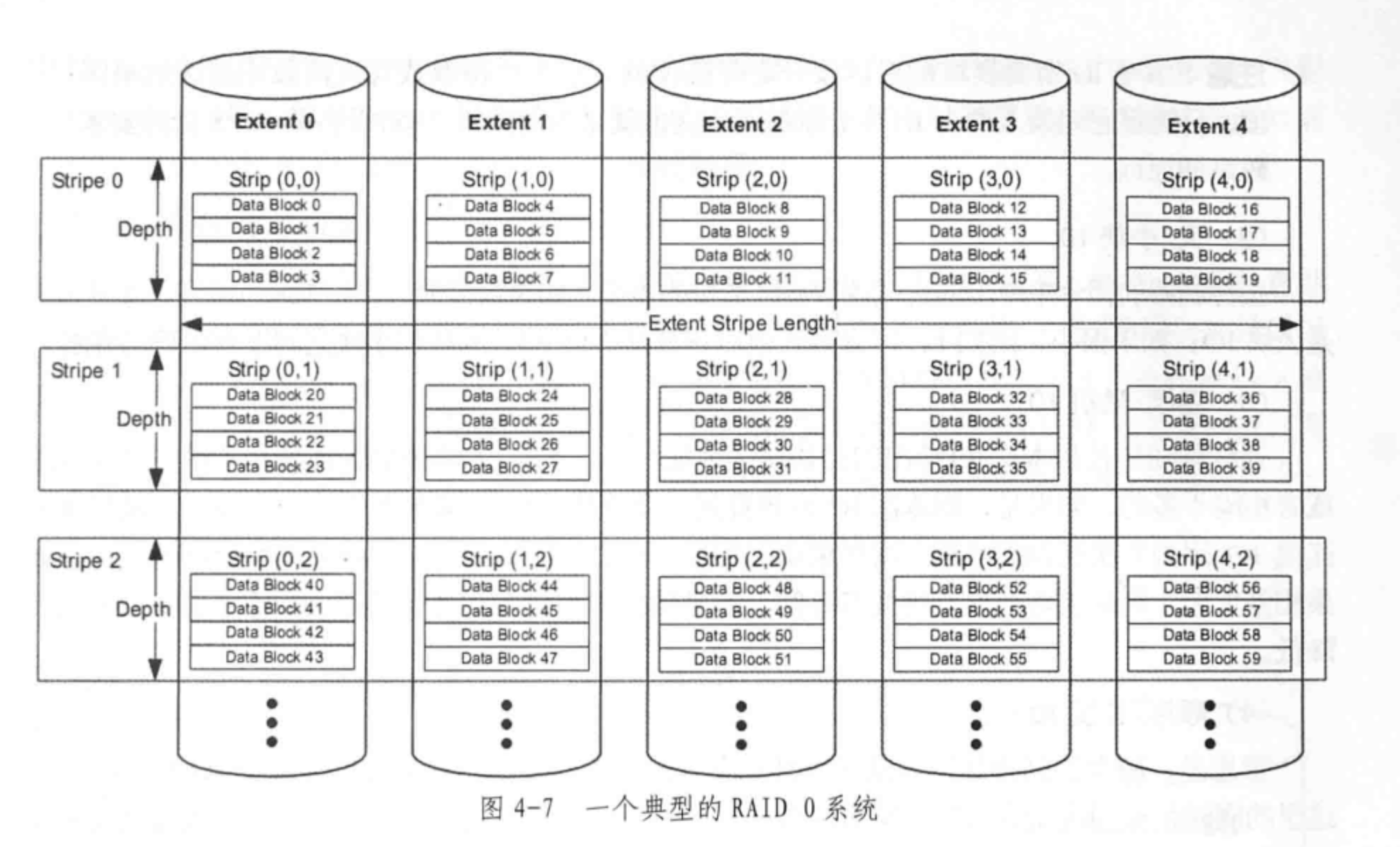
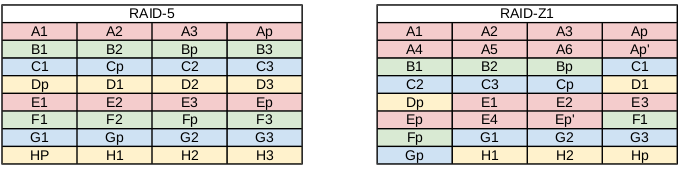
4.3. RAID-Z 与传统 RAID 的不同之处:动态的条带长度·
4.3.1 几个术语:条带、条带深度、条带宽度·
stripe 是指条纹拼接的意思:


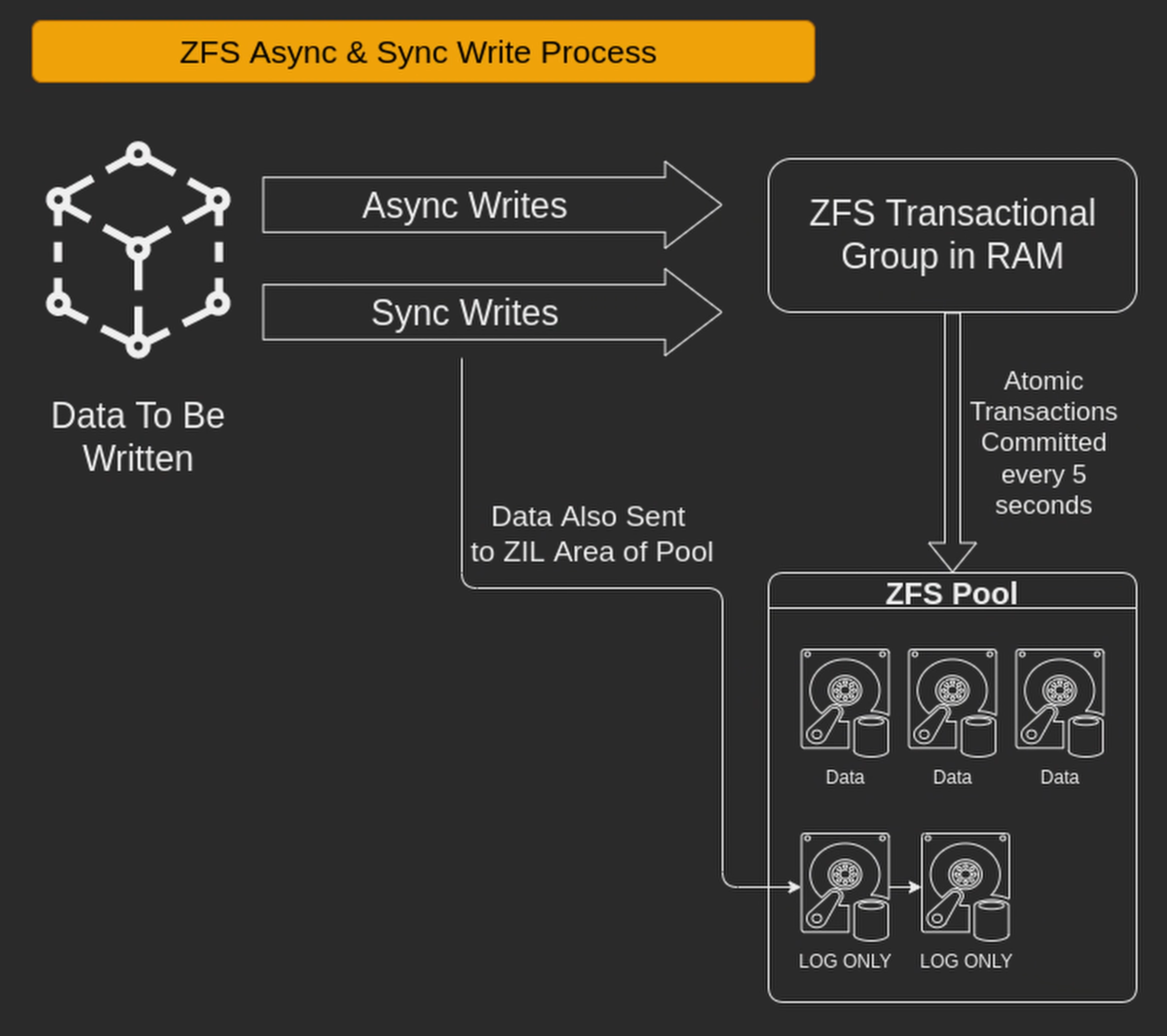
4.4 ZIL 是什么?为什么它会提高 sync 写的性能?·
ZFS Intent Log,简称 ZIL,在同步写时,来自网络的写请求会先落在内存里 (write cache,这个才是真正的写缓存,它是易失性存储),形成一种叫 Transaction Group 的内存型数据结构。Transaction Group 的内容在累积了 5 秒的存量后,会一次性 flush 到硬盘上。在 sync 写时,ZFS 会实时地将写请求直接写到 pool 里一个叫 ZIL 的磁盘型数据结构上。事实上,无论你加不加 Slog vdev,你的同步写的 pool 里都有 ZIL. 在不加 Slog 的情况下,ZIL 和普通数据都存储在同一个或同一组 vdev 上,所以 ZIL 的读、写会与其他读写任务产生 I/O 竞争,所以开启同步写之后,dataset 的性能会大幅下降!这种性能下降在大量随机写入的情况下尤其明显。
而异步写则不然,当有应用请求磁盘写入时,ZFS 会直接给应用 return 写入完成。事实上,所写的数据并没有真正落入磁盘,而是存储在内存里。ZFS 异步写实际上欺骗了应用程序,但是异步写带来了很高的性能。一般情况下,用 NVMe 加速后的同步写也无法在速度上比肩异步写。根据我的实验,用普通 NVMe 做 slog,同步写能达到异步写的百分之七十的速度。
4.4.1 (高级) ZIL 的原理·
ZFS 文件系统中,同步地将数据从内存到硬盘上主要由三种方式:
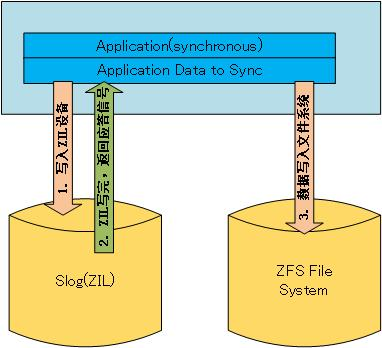
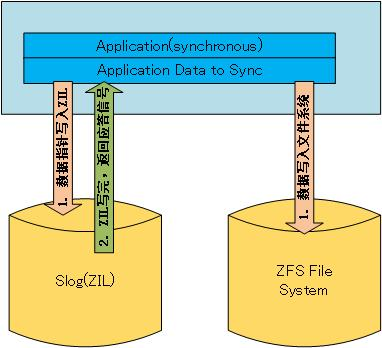
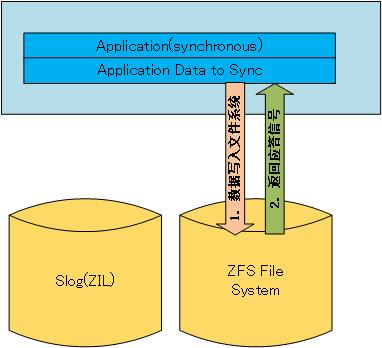
从上面三幅图来看,由于 ZIL 设备比文件系统设备要快很多,写完 ZIL 之后应用程序就可以接着做其他的事情,而不需要等待数据完全写入低速的存储设备,这样,效率也就大大提升了。
在默认的情况下,ZFS 是开启 ZIL 写的,既然默认开启,如果没有存储池中没有 ZIL 设备该怎么办?这时,ZFS 会在文件系统中划出一块空间来作为 ZIL 设备使用,上面方式一的图也就变成下面的样子。
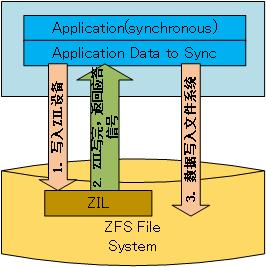
从图中可以看出,这样的 ZIL 设备,速度上与文件系统所在磁盘是一样的,而且还要白白写两次数据。也就是说这并不能提高 ZFS 的性能。所以说:ZIL 设备的选择上,要选择 SSD 这样的高速设备,尽量不要选择低速的机械盘。机械磁盘受顺序写和随机写的性能影响是相当大的。假设这样一种情况:往文件系统中写涉及到随机写,而 ZIL 的写基本上是用完就扔(绝对不会被读取),那么会有大段的连续空间,这么一来也还是能提高一下性能的。
4.4.2 ZIL 总结·
其实 ZIL 对性能的提升主要就是一点:减小写数据延时。通过高速的存储设备迅速响应应用程序给出的写数据请求,而不把时间浪费在等待数据写入慢速设备的过程中。
4.4.3 ZFS Slog 实战:傲腾 900P·
ZFS 的 Slog 设备最好采用单线程、单队列写入速度快(Q1T1 值高)、寿命久的设备。因为 ZFS 诞生比较早,所以最初的设想是以一个 15000 转的机械硬盘作为 Slog,没想到后面有 NAND 技术横空出世,再后面又有 Intel Optane 技术推向市场。目前来看,比较适合做 Slog 的设备就是傲腾。傲腾 900P 这种第一代民用产品,就能在 Q1T1 上完全击败现有的旗舰民用 TLC 固态硬盘,三星 980 Pro、Plextor M10P 等均不是其对手。
在这里我们采用性价比比较高的傲腾 900P 280G U.2 版本做示例。前面说过,Slog 并不需要很大的容量,所以 280G 显然是有点浪费了。而 TrueNAS 系统在 Web GUI 上只能将一整块硬盘作为分配单位,是不能将一个硬盘的某个分区作为分配单位的。所以必须要用命令行对磁盘进行分区,然后再用命令行将合适容量的分区分配给存储池做 Slog.
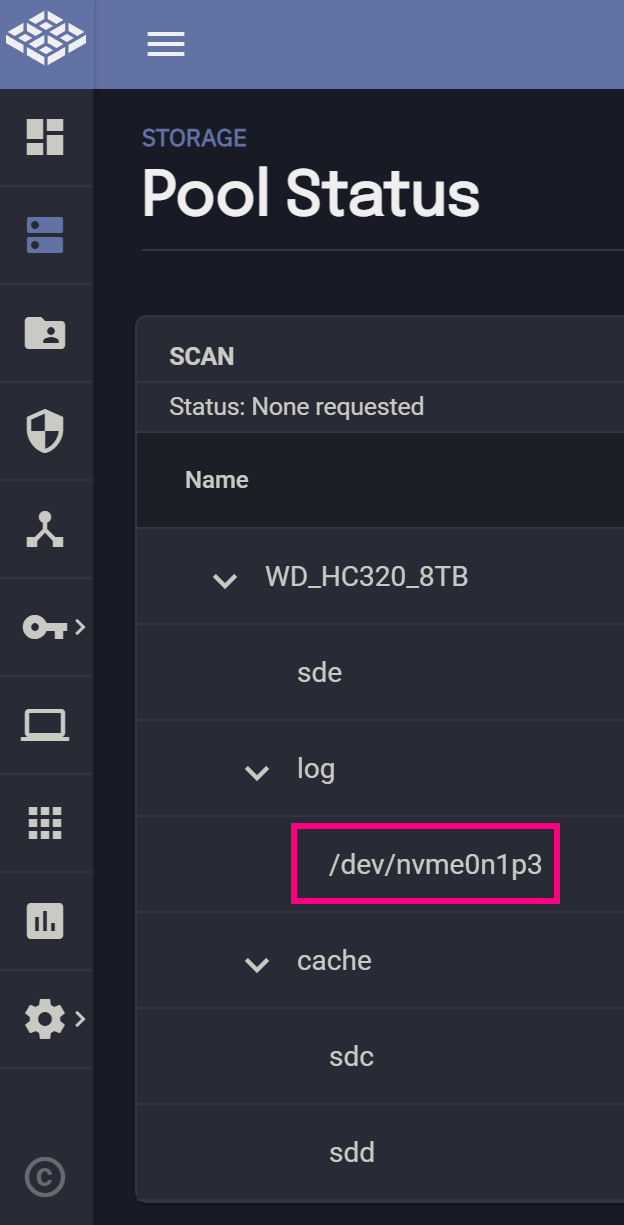
分区部分我们采用 cfdisk 命令来做。首先在 Web GUI 里查看一下傲腾的虚拟路径。

输入命令进入 cfdisk 的 TUI 页面。
1 | # root 用户 |
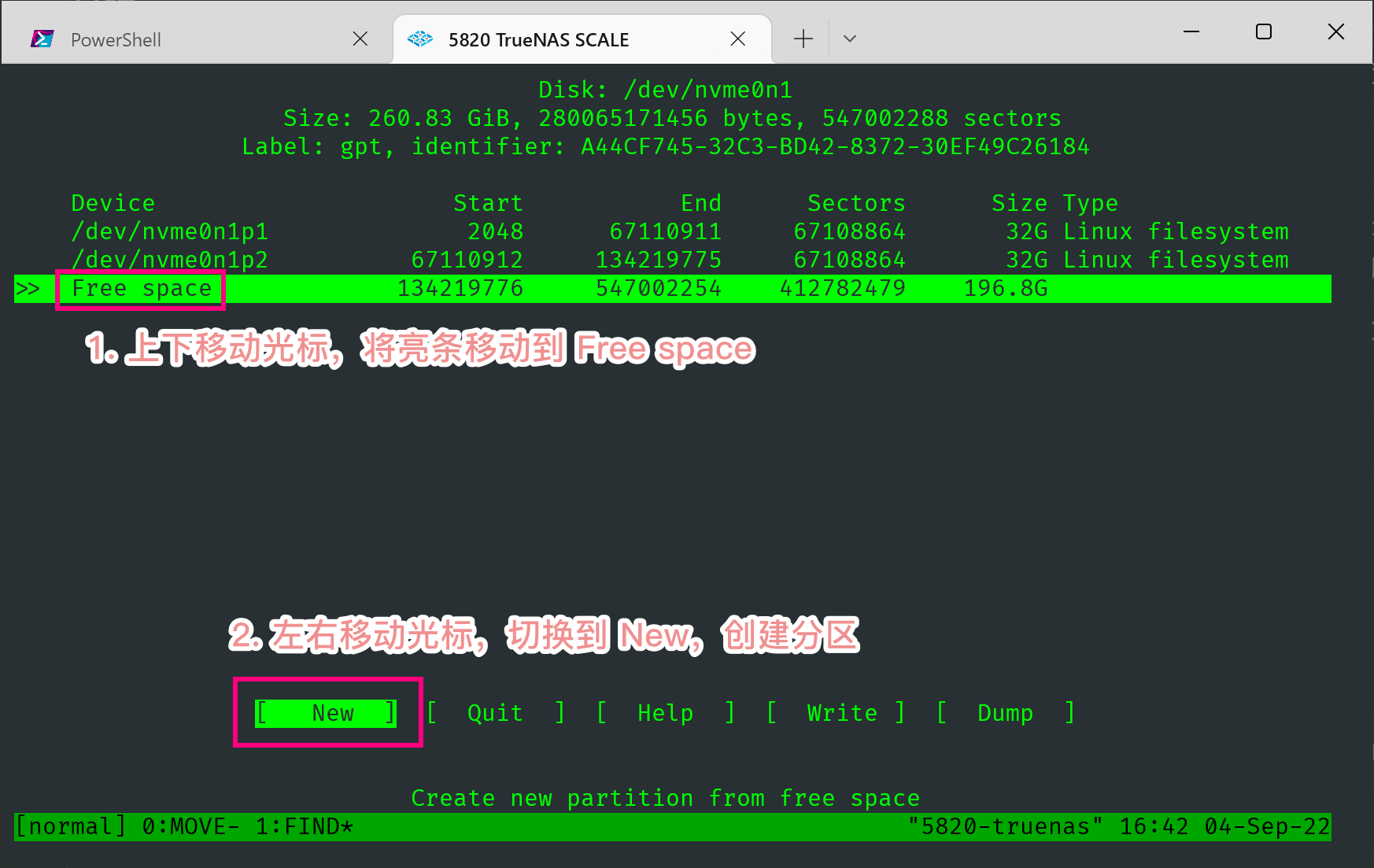
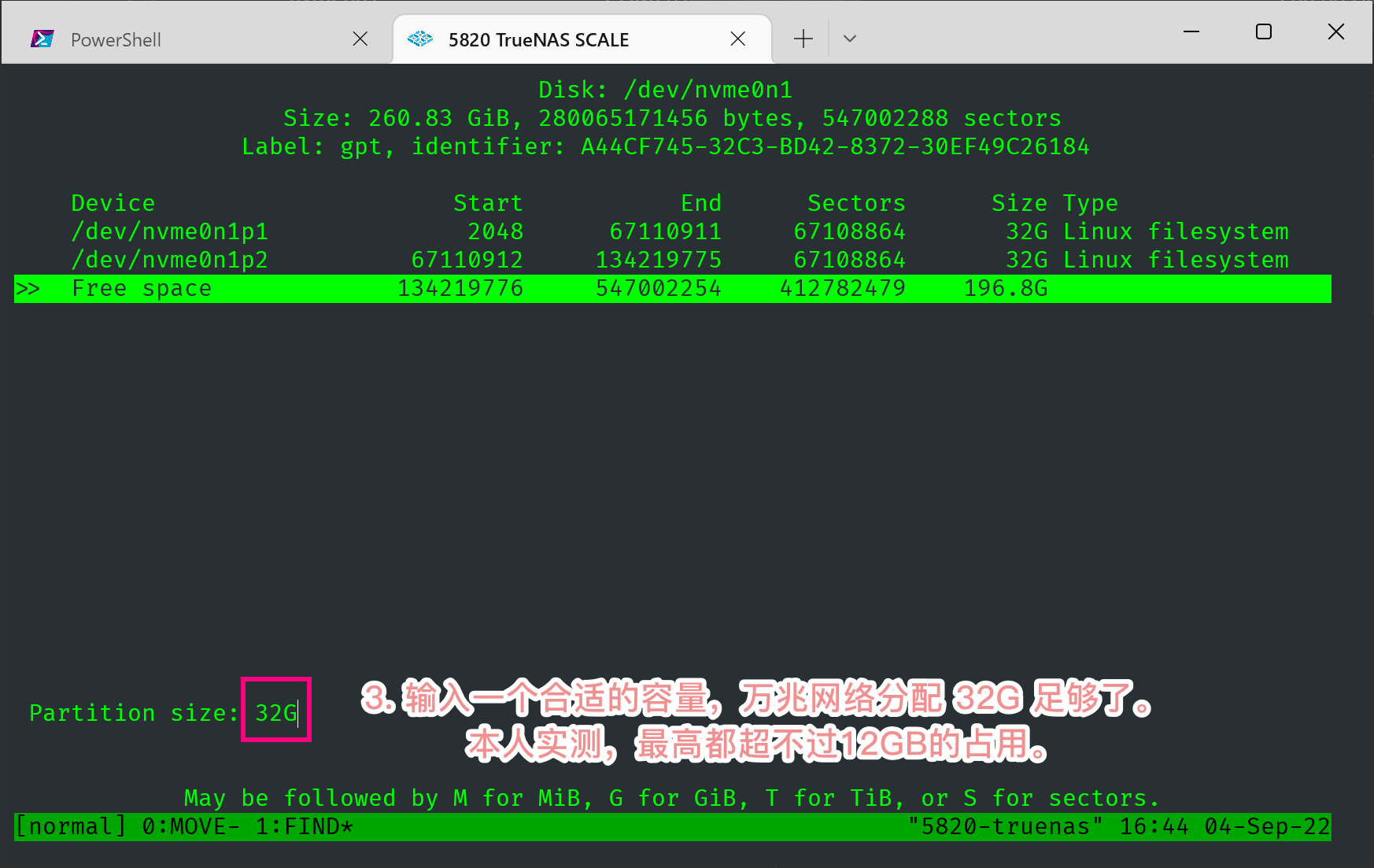
此后你会得到一个类似 /dev/nvme0n1p3 的 Device,这个后缀 p3 就是 /dev/nvme0n1 这块盘的第三个分区。记住这个名字。
1 | # root 模式下操作。给 pool 添加 slog 设备 |
如此一来你就能看到这个分区被加载到 pool 里了。
查看zpool iostat,也可以发现 pool 里多了一个 32G 的 log 设备,这证明我们操作成功。
1 | capacity operations bandwidth |
通过重复这个操作,你可以为不同的机械 ZFS 阵列添加合适容量的 Slog.
注意,zpool iostat 显示的一串十六进制字符是 Partition GUID,可以在 /dev/disk/by-partuuid/ 目录里看到这些 GUID 值。如果你调整了硬盘的顺序(如拔插、更改虚拟机的直通顺序),GUID 值也不会改变,因此不用担心 ZFS 会因为硬盘顺序改变而丢失阵列。
4.4 ZFS 中级 Q&A·
Q&A 1. 写完 ZIL 断电怎么办?·
答:ZIL 设备是不会被应用程序读取的,那如果数据写入 ZIL 设备,还没有来得及写入文件系统该怎么办呢?其实,说不会被读取并不是绝对的。在一种情况下 ZIL 会被读取(也仅仅只有这一种情况),就是在系统重新启动之后,ZFS 模块被加载后。ZFS 模块加载后的第一件事就是看上次关闭之前是否有未完成的工作。如果有,就需要创建一个 Claim 类型的 ZIO,来完成这个工作。
Q&A 2. 到底什么是同步写?·
答(重点):同步写,到底是谁与谁同步?按照我的理解,是 ZIL 写与 write cache 写同步。应用产生的数据会 pending 在内存,等待凑齐一个五秒的 Transaction group,同时这些数据也会写入到 ZIL. 因此 ZIL 与 Transaction Group 的写入是同步的。这是同步的真实含义。异步写因为没有 ZIL,所以就不存在 ZIL 与 Transaction group 的同步,叫异步写也没什么问题。所以你也能理解在没有 Slog 的情况下为什么性能太低了,因为无 Slog 时,ZIL 和上一组 Transaction Group 的 Commit 都在用 pool 里的同一个 vdev,一组数据实际上被写入了两次,一次是 ZIL,一次是 Transaction Group 的 commit,代价不可谓不大。
Q&A 3. Slog 是什么?·
前面我们看到了,ZIL 是在 sync 写的情况下才起作用,而且默认情况下 ZIL 存在于 pool 中的某个地方,因此 ZIL 事务会与磁盘的正常 I/O 形成竞争关系。那么我们不禁想问,能否把 ZIL 放到别的磁盘上以降低 data vdev 的负载呢?答案是肯定的,这就是 Separated Log,也就是 Slog!
Q&A 4. Slog 要怎么弄才最好?容量、速度等方面谈谈·
一般而言,假如你用万兆网卡,那么极限速度是 1.25GB/s,因为 ZIL 的数据每 5 秒就 flush 到磁盘上,因此 Slog 有 6.25G 就够了。然而事实没有这么简单粗暴,还要考虑 data vdev 的实际性能与持续写入时间。
此外,将 dataset 设置为 sync always 模式之后,所有往 dataset 里写东西的操作都是同步的。因此输入来源不仅来自于网络,还来自于本机应用、本机的其他 dataset,后面这些数据来源的速率在一般情况下远比万兆网络要高!比如我个人使用存储的习惯是将下载盘独立到存储盘之外,这样主存储池就不会频繁读写,相应的在突然断电情况下数据损坏的概率也会小一些。在这种情况下,建议 Slog 可以稍微设置大一些。
Q&A 5. 什么场景适合开启同步写 or 异步写?·
个人认为,如果你有傲腾做 Slog,那么大可将所有的机械阵列都开启同步写。当然,前提是你的傲腾设备足够可靠,它坏掉的概率要小于等于 data vdev 损毁的概率。
同步写的适用场景
- NFS
- 虚拟机
- 数据库
异步写的适用场景
- 大容量影音数据库
- PT 下载
5. ZFS 数据完整性·
对于很多的应用环境下,文件系统中数据完整性(Data Integrity)的重要性甚至高于文件系统的读写性能。因此,目前的文件系统或是存储系统都在数据完整性方面下了一番功夫。使用 Checksum 就是提高数据完整性的一种方式。
5.1 CheckSum 数据校验·
5.1.1 一般的 Checksum 校验方式·
对于一般的文件系统来说,一个数据块的 Checksum 值是和对应的数据存放在一起的(如下图所示),在读取数据的同时就包含了对应数据的 Checksum 值,以此来检查数据是否有错误。

这样的 checksum 方式可以检测到数据块中某个位发生错误。但是这样的校验方式存在很多问题,比如无法检测到静默数据错误(Silent Data Corruption)。这种错误的发生一般是来自硬件本身,比如磁盘损坏,硬件驱动错误,RAID 卡损坏等等。举一个形象点得例子,假如我们在网上买了件瓷器,卖家将完整的瓷器包装好,交给快递公司,快递公司之后将瓷器原封不动地交给我们手中时,这里面的瓷器一定是完好无损的?显然是不一定的,说不定运输过程中给颠碎了。同样磁盘也有这样的问题,这些问题虽然难以被检测到,但是这些问题确实经常发生,严重影响了数据的完整性。在 ZFS 文件系统之前,还没有文件系统能够处理好这些问题。而 ZFS 在设计时就将这一切考虑到了,我们来看一下 ZFS 是如何通过 Checksum 来实现完整性校验的。
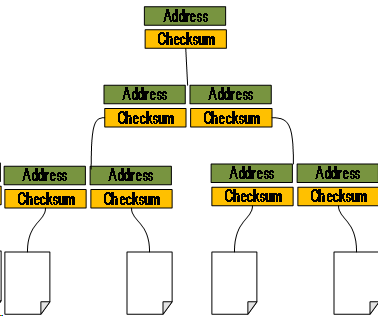
5.1.2 ZFS 的 Checksum 校验方式·
在 ZFS 文件系统中,数据的 Checksum 值并不是与数据存储在一起的,而是将数据的 Checksum 值存储在指向它的块指针中(如下图所示)。这样数据块的损坏并不会影响到 Checksum,这样 ZFS 就维护了这样一棵树,每个节点都包含了它的子节点的 Checksum 值。(这里留下一个问题,这棵树的根是没有父节点的,它怎么校验?)。通过这棵树,ZFS 可以完成自检工作,在自上而下的自检过程中,由于上面的 Checksum 值是经过验证的的,所以如果下面的数据发生错误,将很容易被检测出来。
5.1.3 ZFS 与 ext4 文件系统数据校验对比实例·
下面,我们将通过一个实例来看看,如果我们偷偷修改了磁盘上的数据,ZFS 和 ext4 文件系统将会有怎样的反应。
实验 OS:Ubuntu 12.04(启动磁盘文件系统为 ZFS)。
实验的主要流程:
- 通过分别在 ext4 文件系统和 ZFS 文件系统中分别放置一个相同的文件
allocator.txt. - 通过文件的在磁盘中的信息,找到第一个块位置(
N),以这个 blcok 位界限,把整个磁盘分成三部分,N 之前的部分,N,N 之后的部分 - 通过
dd命令将三个部分分别独处放到三个不同的文件中 - 修改分开后的 N 的文件,也就是文件的开头所在的 block
- 将三部分重新整合,重新挂载文件系统,看文件是否已经被修改过,文件系统能否发现文件已经被修改了。
首先,我们创建两个文件作为磁盘,分别在两个磁盘上创建 ZFS 文件系统和 ext4 文件系统。
1 | # dd if=/dev/zero of=forZFSdiskfile bs=1024k count=100 |
其次,我们分别放两个同样的文件到这两个新建的文件系统中。我们放入的文件是 ZFS 的首席设计师 Jeff Bonwick 之前提出的一篇大作:An Object-Caching Kernel Memory Allocator
1 | # debugfs forextdiskfile |
我们来看一下,allocator.txt 文件的前几行信息:
1 | --------------------------------------------------------------------------------------------------------------------- |
由于我们在创建 ext4 文件系统时候就已经确定了,该文件系统的 Block 大小为 4096 Bytes. 同时我们注意到,在放置文件之前,文件系统的空闲 block 数目是:23760,放置之后空闲 block 数目是 23747. 也就是说,allocator.txt 文件一共占用了 13 个 block. 同时它对应的 inode 为 13. 通过 debugfs 我们也可以看到,它的 13 个 block 位置:(0-12):24592-24604.
下面,将把 forextdisk 分成三个部分,修改文件,然后重组,确认:
1 | # dd if=forextdiskfile of=/tmp/forextdisk_part1 count=24592 bs=4096 |
6. ZFS 性能调优实战(重点)·
6.1 ZFS 数据集的 Record Size·
6.2 ZVol 与 iSCSI 的 Block Size 设置·
建议根据 iSCSI target 的用途设置合适的 Block Size.
I/O 和带宽都是越高越好,但是二者是矛盾的。
6.3 提升性能的终极法则:建立与应用需求匹配的 dataset·
7. 番外:文件共享中的几个陷阱·
陷阱 1:WebDav 的文件所属信息修改·
某些用户在了解了 webdav 之后,想在共享里开启 webdav,然后根据网上某些教程就直接把 dataset 的 owner 设置为了用户 webdav.
因为 wevdav 基于 HTTP,所以文件访问权限也要跟架设 web 服务器一样,只能让 web 服务器访问特定的目录。wevdav 服务器所使用的用户是 wevdav,因此在 TrueNAS 的存储 Permission 页面里将数据集的 ACL 添加一条即可,没必要把数据集的所有权交给 wevdav 用户。因为你的数据集里可能有很多文件了,很多 docker 容器可能依赖这些文件的权限关系,所以不宜递归式地更改权限!
陷阱 2:NFS 的用户认证·
个人认为,NFS 的很多特性非常坑爹,如无必要不建议使用 NFS,特别是容器化部署某些服务时要避免使用 NFS 服务。NFS 服务是没有强认证的,因此只适合在内网里架设该服务。
8. 终章:ZFS on Linux (ZoL)前景远大·
FreeNAS 自诞生之初就采用了 FreeBSD 内核,作为正统的 UNIX(而非 Linux 那种类 Unix),FreeNAS 继承了 BSD 内核优雅、小巧、稳定的特点。然而随着 Linux 在服务器领域称霸,越来越多的服务器厂商仅提供 Linux 和 Windows Server 的驱动,比如 Mellanox 的网卡在 FreeBSD 内核上就没有原生驱动。哪怕 Mellanox 的少部分网卡能在 FreeBSD 上跑起来,其驱动大概率也是 Linux 版重新编译出来的,稳定性不如原生 Linux. 这种硬件资源匮乏的局面到这很多玩家不喜欢 FreeNAS.
此外,ZFS 的源代码虽然开源,但是采用的并不是 GPLv2 协议,而且恰巧 ZFS 的开源协议和 Linux Kernel 的开源协议并不一致,两者不能合并成一个代码库用同一套源码、License 发布。不能合并就代表适配工作需要异步进行,ZFS 的人不考虑兼容 Linux,Linux 的人也不考虑兼容 ZFS,这就很难受了。至于为什么国外程序员如此重视开源协议,那这就是另一个极为复杂的社会、科学问题了。