存储迁移:zfs send recv 还是 rsync?
坑边闲话:存储系统随时面临扩容的考验。在不重建存储池的情况下,使用 ZFS 自带的 expansion 方案也是可行的。然而 data vdev 变多之后,占用量不均衡的现象很令人烦恼。这种不均衡拉长了 scrub 所需时间,限制了 I/O 并行度。要彻底解决这个问题,唯一可行的方案就是数据迁移。
1. ZFS 添加阵列的弊端·
在传统认知里,RAID 重建是很危险的操作。比如我们可以往 RAID-5 里添加硬盘,此时会产生一次重建:RAID 卡会按照一定的原则,将原阵列中的一部分数据和校验值分摊到新的硬盘上,使得新阵列的所有硬盘具有相同的容量占用。由于重建过程耗时良久,而且系统会进行高强度的读后写,导致磁盘处于高负载状态。一旦出现高温或电源供给不稳定,极容易造成阵列损毁。在机械硬盘时代,阵列重建过程耗时非常久。尽管 SSD 可以让重建工作变得更高效,但这依旧是个麻烦,而且会带来服务降级,甚至造成服务的中断。
作为对比,ZFS 支持实时扩容。ZFS 的操作很简单,当目前的存储池占用达到 80% 左右的时候,系统提示告警。当然,80% 只是一个常见值,用户可以自行设定阀值。在收到告警之后,用户最好添加一个一模一样的 RAID-Z 到现有的阵列组里(当然,添加一个任意拓扑结构的 data vdev 也是可以的,但是不推荐这样做),新老 RAID-Z 以 stripe 的形式提供池化存储服务。
然而这样的问题很明显:新旧阵列的数据占比不均衡,即老 RAID-Z 已经接近满占用,但是新 RAID-Z 几乎是零占用。此时往存储池里写数据,在极端情况下只有新 RAID-Z 在接收,老 RAID-Z 一点写入量都没有。
可以简单计算一下系统的文件占用:
- 第一次扩容
- 扩容后的占用布局:(
0.8,0) - 扩容后的占用量为 $\frac{0.8+0}{2}=0.4$
- 可写入总计 0.8 个阵列可用容量。
- 在此达到全池占用 80% 后,占用布局为 (
1.0,0.6),写入到 0.4 个阵列可用容量时出现降速。
- 扩容后的占用布局:(
- 第二次扩容
- 扩容后的占用布局:(
1.0,0.6,0) - 扩容后的占用量为 $\frac{1.0+0.6+0}{3} = 0.53$
- 可写入总计 0.8 个阵列可用容量。
- 再次达到全池占用 80% 后,占用布局为 (
1.0,1.0,0.4),到达 80% 占用前,全程只有两个阵列的写入速度,且不降速。
- 扩容后的占用布局:(
- 第三次扩容
- 扩容后的占用布局:(
1.0,1.0,0.4,0) - 扩容后的占用量为 $\frac{1.0+1.0+0.4+0}{4}=0.6$
- 可写入总计 0.8 个阵列可用容量。
- 再次达到全池占用 80% 后,占用布局为 (
1.0,1.0,0.8,0.4),到达全池 80% 占用前,全程只有两个阵列的写入速度,且不降速。
- 扩容后的占用布局:(
- 第四次扩容
- 扩容后的占用布局:(
1.0,1.0,0.8,0.4,0) - 扩容后的占用量为 $\frac{1.0+1.0+0.8+0.4+0}{5}=0.64$
- 可写入总计 0.8 个阵列可用容量。
- 再次达到全池占用 80% 后,占用布局为 (
1.0,1.0,1.0,0.7,0.3),到达全池 80% 占用前,全程先有三个阵列的写入速度,写入 0.6 个阵列可用容量后,降速为双阵列写速。
- 扩容后的占用布局:(
由此可见,每次扩容后的新可用空间永远不变,但是 pool 的占用比一直在增高,只是后续随着总空间的容量越来越大,分母越来越大,写入的占用比例增速不再明显。至于写入速度则比较难以计算,但总体也是二到三个阵列 stripe 的速率。
下面简单展示每次扩容一个阵列达到阀值时的阵列占用率。
1 | #1 ==> 0.8 |
为了进一步澄清这个事实,笔者提供了一段 Python 代码,可以计算出扩容后的布局:
1 | # 单阵列的最高占用比例 |
将结果稍微可视化处理,可以得到下图:
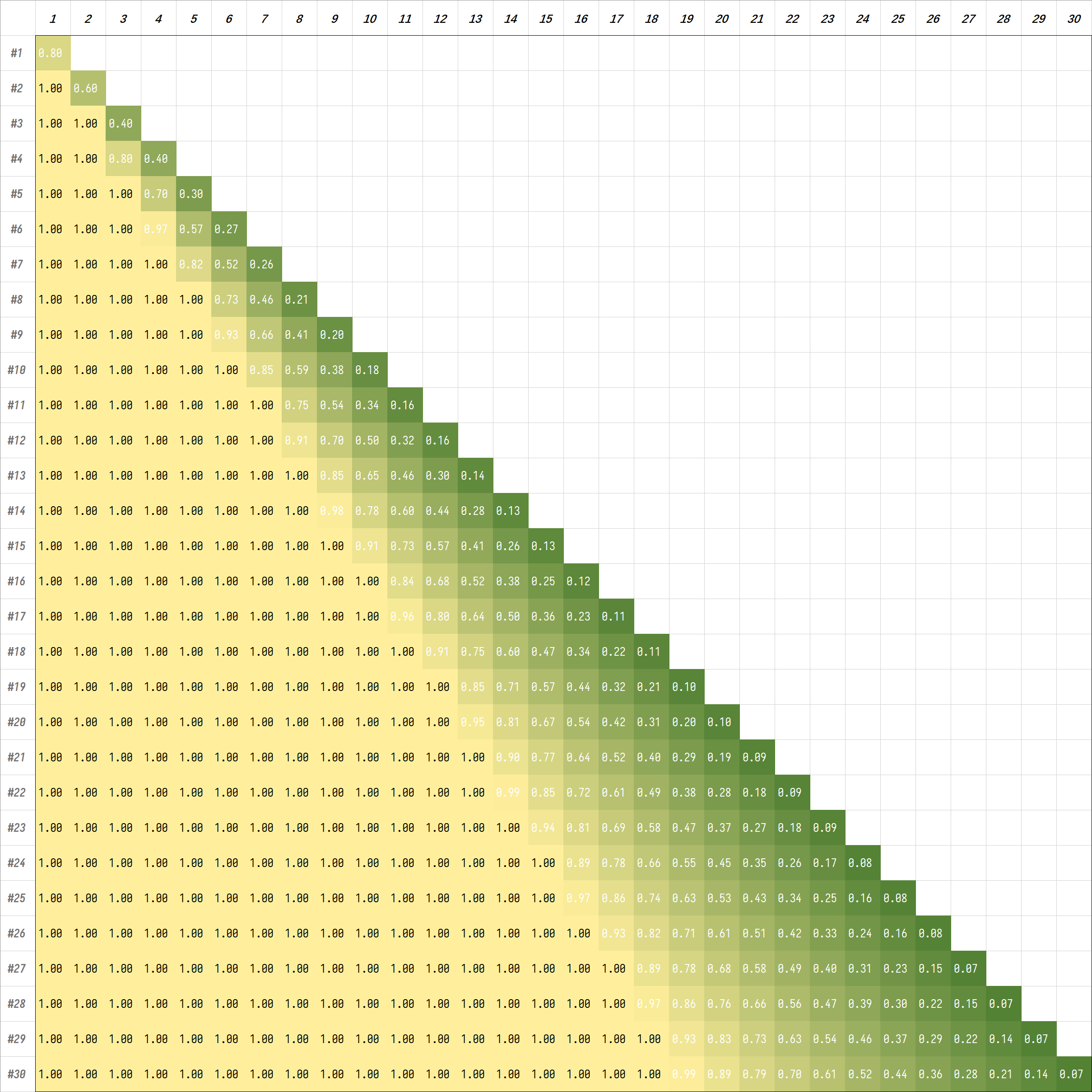
根据以上计算,我们得出两个重要结论:
- 通过逐个添加同规模、同容量的 data vdev 到现有存储池以实现扩容,可以保证每次扩容后新的可用容量为添加的新阵列的可用容量。
- 通过上述扩容方式,文件在不重写的情况下,已写入的逻辑块将不会均匀分布在所有磁盘中。这带来的好处是损毁某些阵列,不会造成全部数据的丢失,但弊端是读取性能比较一般。因此 ZFS 建议单阵列的读取性能应该设置为服务的极限读取性能,如果单阵列的性能无法达到服务的要求,则应该在创建阵列的时候考虑增大阵列的可用磁盘数量,即增加 vdev 条带宽度。
2. 如何解决 ZFS 扩容带来的问题?·
一般有几种常见策略可以解决上述问题:
- 阵列的手动平衡。通过检测文件的时间戳,判定出哪些文件在哪个阵列里。随后逐个重新写入,即可完成平衡。要做到精准的话,需要每次添加阵列之前都做一次文件分布记录,比如使用
tree命令将目录导出。- 缺点:繁琐无比,而且需要耗费大量的精力。
- 优点:可以保证平衡占用。
- 寻找一个空余的大空间,将所有数据挪过去,再挪回来。
- 缺点:成本高,一般人很难找到一个合适的大空间。几百 TiB 的数据就需要几百 TiB 的临时空间,这几乎不可能做到。此外,还有两次完整传输带来的时间成本。
- 优点:可以做到严格的再平衡。
今天我们的主要思路是方法 2,即重新写入。为了实现重新写入,一般有几个常用的方案:
- 使用
rsync命令按文件进行搬迁。 - 使用
zfs send和zfs recv管道传输整个文件系统。
从性能上看,方案 2 更加合适,它可以实现 full stream,最大化地使用到磁盘的极限性能。rysnc 的速率也不慢,但是很难摸清楚它的块读取策略。
2.1 最大化 rsync 的性能·
rsync 用来做文件迁移是非常好用的。
使用 root 权限执行 rsync 可以保留文件的所有属性,包括权限、时间戳等。使用 rsync 的时候,最好使用 -a 参数,这样可以保留所有的文件属性。
1 | rsync -avh --progress /source/directory/ /destination/directory/ |
2.2 理解 zfs send / zfs recv 的问题·
我们设想有如下存储场景:
- 单个 RAID-Z 的条带宽度为 4,即 4 盘 RAID-Z;
- RAID-Z 磁盘组的数量为 3,即该存储池经历过两次扩容。
- 现在每个磁盘的容量是 18TB,需要将该存储池的数据迁移到一个所有盘均为 22TB 的新存储池中。
同时,假设有如下理想化的读写场景:
- 开始只有一个 data vdev;
- 当且仅当现在 pool 中所有 data vdev 都已写满时,再添加一个与上次所添加的 vdev 规格完全相同的新 data vdev;
- 只写入或读取,不删除、改写,而且所有 record 都具有相同的大小;
- 所有 record 均不可压缩。
由于同一时刻仅有一个 data vdev 可写,因此一个 record 会被写入同一个 vdev,绝对不会被条带化拆分到不同 vdev.
下面提出笔者的两个猜想。
2.2.1 尊重 record 的时间顺序·
zfs send 的时候,先从一号(最老的) data vdev 里读取三个 record,然后分别写入到新存储池的三个 data vdev 中。如下图所示:
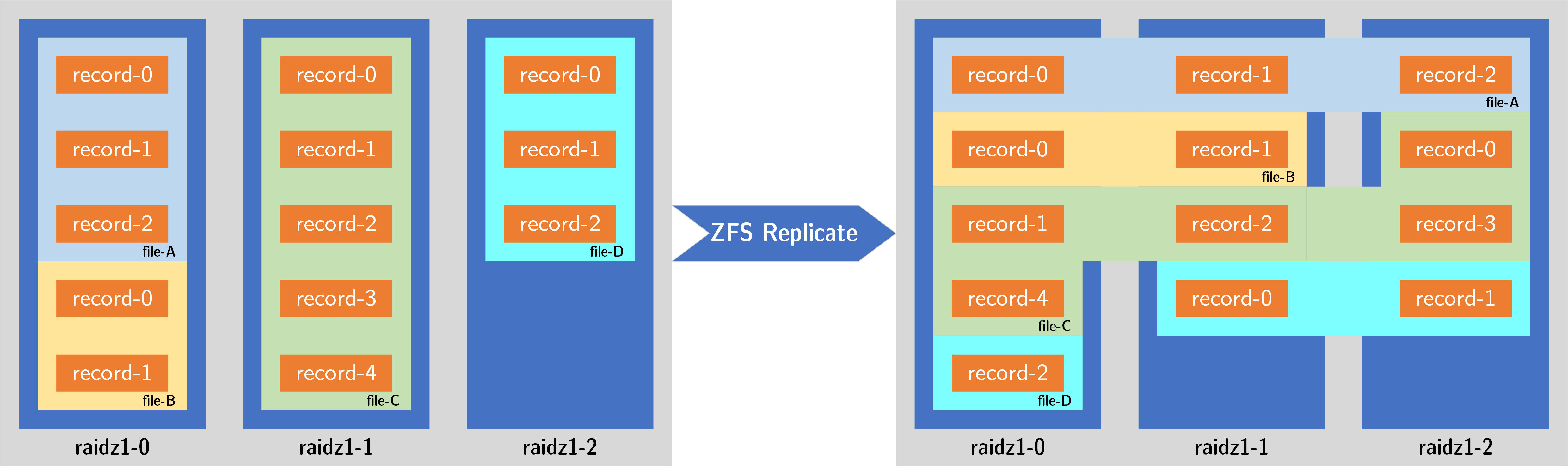
这样做的效果非常理想,因为老 data vdev 里记录的 record 逻辑块来自于老的文件,那时候整个 pool 只有当前这一个 data vdev. 写入时将这些块平均分散到所有的 RAID-Z 里,无疑提升了新存储池的并行度,此后读取这个文件时,将不再是只从一个 data vdev 里读取,而是从三个 data vdev 里同时读取。如此完成数据迁移,将带来平均的 vdev 占用以及更高的单文件读取性能。
2.2.2 不尊重时间序列·
如果 zfs send 并行地从老 pool 的三个 data vdev 里读取 record,然后分别写入到三个新的 data vdev 里。由于三个现有的 data vdev 占用率不等,因此后期会出现只剩两个 vdev 需要读取、只剩一个 vdev 需要读取的局面。如下图所示:
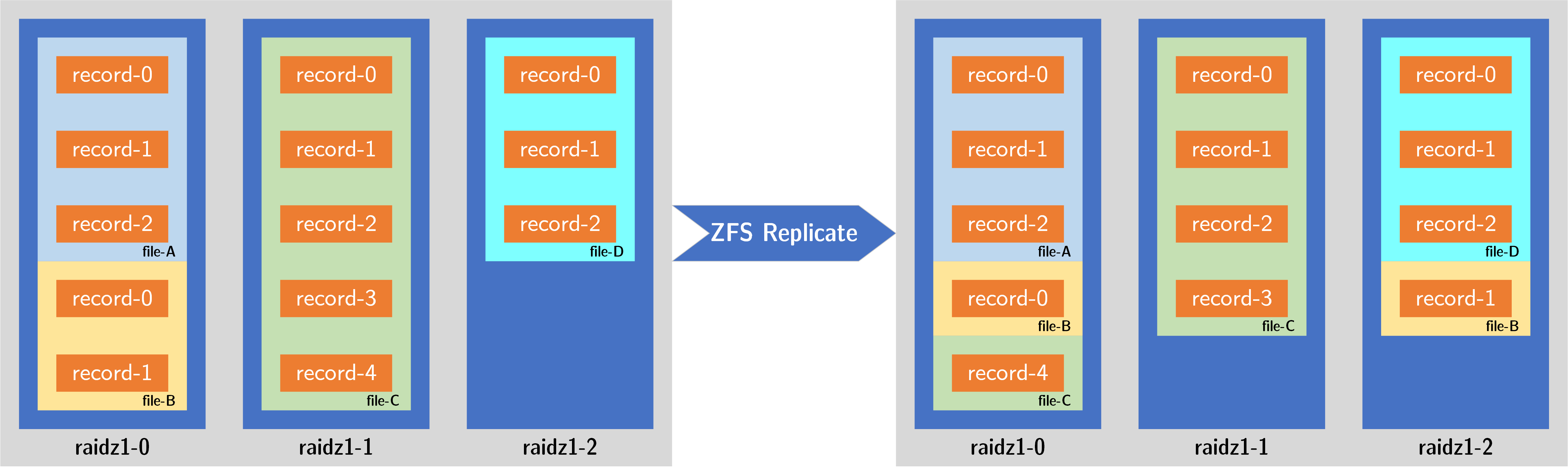
- 就像地质领域的沉积结构一样,老 data vdev 里的 record 基本来自先前对于同一批文件的写入。由于并行读取、并行写入策略,原先同期的 record 也被写入了同一个新 vdev,并没有分散到多个 data vdev.
- 由于最老的 data vdev 占用率最高,所以到了后期,只剩最老的 data vdev 没有搬迁完毕。此时该 data vdev 的剩余部分将会平均分配到三个新 RAID-Z 里。这反而导致最后部分的数据被平均分散到新的 vdev 里。
然而,这样处理的结果依旧不够明确,因为我们不知道搬迁的前期,新旧 RAID-Z 的读取和写入是否有一一对应的关系,如果答案是肯定的,那么将保持原有的布局,不会提升性能;反之,ZFS 可能会采取一种调度策略,尽量保证从一个老 RAID-Z 里读出的块序列,可以随机分配到新的三个 RAID-Z 里。那么答案是什么呢?需要做实验才清楚。
2.2.3 最终答案·
ZFS Replication 核心机制如下:
zfs send的本质:zfs send创建的是一个数据流,这个流是基于文件系统/快照的逻辑结构生成的。它会按照 ZFS 对象集 (ZOS) 中的块指针 (Block Pointers) 顺序(大致可以理解为文件系统中对象的创建/修改顺序,以及元数据结构)来读取数据块。zfs send不关心这些逻辑块在源池的哪个物理 vdev 上。它只是请求逻辑块,ZFS 底层会从相应的 vdev 中读取。- 因此,数据流的顺序,尤其是在这种理想化的写入场景下(无删除、无改写、顺序填充 vdev),会很大程度上反映数据写入的时间顺序。最先写入的 record (在最老的 vdev1 上) 会最先出现在
zfs send的流中。这证明,笔者的猜想 1 是正确的。
zfs recv的本质:zfs recv接收这个逻辑数据流,并在目标池中创建对应的文件系统结构和写入数据块。- 当
zfs recv需要在目标池中分配空间写入数据块时,它会使用目标池的 ZFS 空间分配器 (space allocator)。 - ZFS 空间分配器在有多个 top-level vdev (如你的新池有3个 RAID-Z vdev) 时,会努力将新的写入均匀地分配到所有可用的 top-level vdev 上,以实现负载均衡和最大化并行性。它并不关心这个数据块在源池的哪个 vdev 上。
因此,猜想 2.2.1 的描述和结果更接近实际情况。
zfs send 会按照数据的逻辑/时间顺序(在本文的理想化场景中这两者高度一致)发送数据。zfs recv 在接收数据时,会利用目标池的分配机制将数据块尽可能均匀地分布到新池的所有三个 vdev 上。
这意味着:
- 数据重新分布:原本集中在老池单个 vdev 上的文件数据,在迁移到新池后,其数据块会被分散到新池的多个 vdev 上。
- 性能提升:对于那些迁移过来的、原先只存在于单个老 vdev 的文件,在新池中读取它们时,可以从多个新 vdev 并行读取数据,从而提升单文件读取性能。
- vdev 占用率平均化:在新池中,所有三个 vdev 的占用率会相对平均地增长(考虑到 ZFS 分配器的目标和实际操作的微小不均)。
总结·
这篇博客讨论了创建 RAID-Z 时需要注意的问题,同时对比了迁移存储的一些方法。
通过分析真实的 ZFS 架构,可以发现 ZFS replicate 是一个非常科学的设计。