RTX 3090 PCIe 3.0 不同通道数量性能测试
坑边闲话:坑边闲话:快过年了,家里什么年货也没买,就剩一张 RTX3090 Vulcan OC,那么是插 PCIe 3.0 x8 好呢还是插 PCIe 3.0 x16 好呢?废话,有条件当然是插 PCIe 3.0 x16 咯。但是两者差别大吗?让我们一起来看看。

作为一个 X299 的老用户,虽然我 PCIe 版本老,但是我通道数量多啊!M.2 扩展卡、U.2 扩展卡、显卡、万兆网卡、SAS-RAID 卡任君选择。
然而,事情的真相是主板的 PCIe slot 插槽数量、带宽分配方式都决定,你不能随便插。就比如我这个某嘉的主板有四条 PCIe 插槽,从上到下分别是
x16_Ax8_B(与x16_B共享带宽)x16_Bx8_C
其中后缀为 B 的共享带宽,用 switch 芯片做切分,且 x16 的优先级更高。于是总带宽就是 16 + 16 + 8 + (4 + 4 两个 M.2) 共计 48 lane,正好全部利用到位。相邻插槽之间是两槽宽度。于是庞大的 3090 最好是插在 x16_A 上,这样你的 3090 会挡住 x8_B,但是 x16_B 会完整留出来,可以插 bifurcation 分叉卡扩展硬盘。
当然,在这种情况下,如果你想在 x8_B 上插双口万兆网卡(x8)、在 x16_B 上插 raid 卡(x8)就不行了,因为显卡挡住了 x8_B. 所以只要用了三槽厚度的 3090,你就必须挡住一个插槽。那你可能会问,把显卡插在 X16_B 上不好吗?当然不好,因为这样会挡住独立的 X8_C,浪费极大!
可怜的我当初以为技嘉的主板 PCIe 插槽和内存插槽挨太近导致无法把显卡插在 x16_A 上,于是我只能插在 x8_B 上。而今天我发现把电脑搬出来放平了,是能把 3090 塞进 x16_A 插槽的。
这就是 NVIDIA RTX3090 的智障之处!背面 12 颗显存发热大,然后就得在背板上做散热,火神和 MSI 超龙还加了热管,这就导致背板厚度比以往显卡厚很多。这在 X299X Aorus Master 这种主板上就是灾难。

看另一个技嘉主板:

OK,那么我从 X8 换到 X16 之后,性能有提升吗?看图:
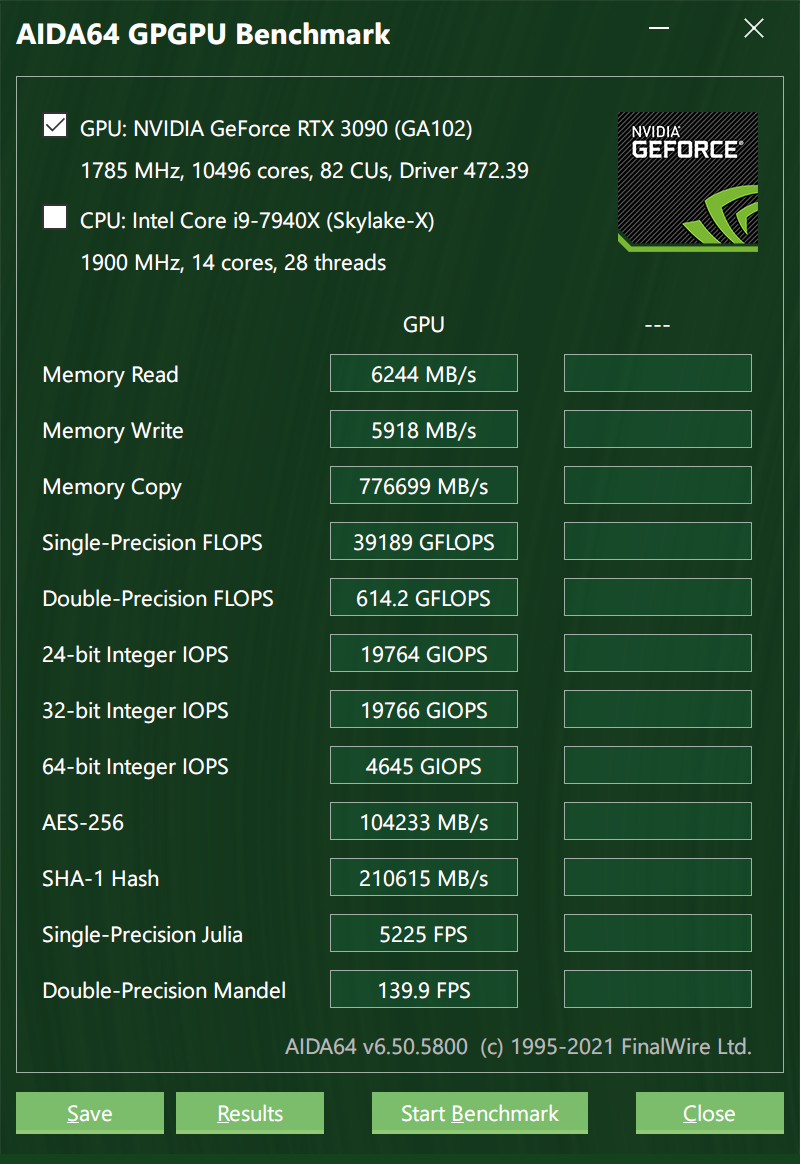
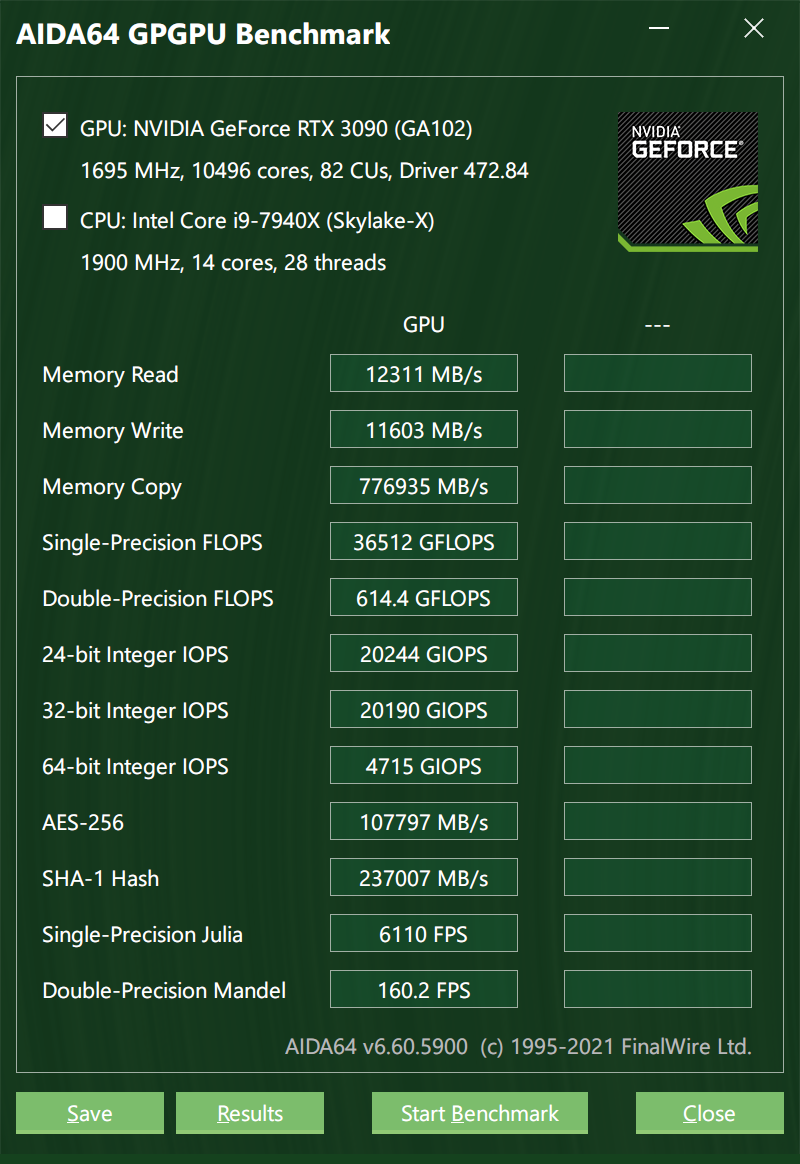
画个图看一下对比:
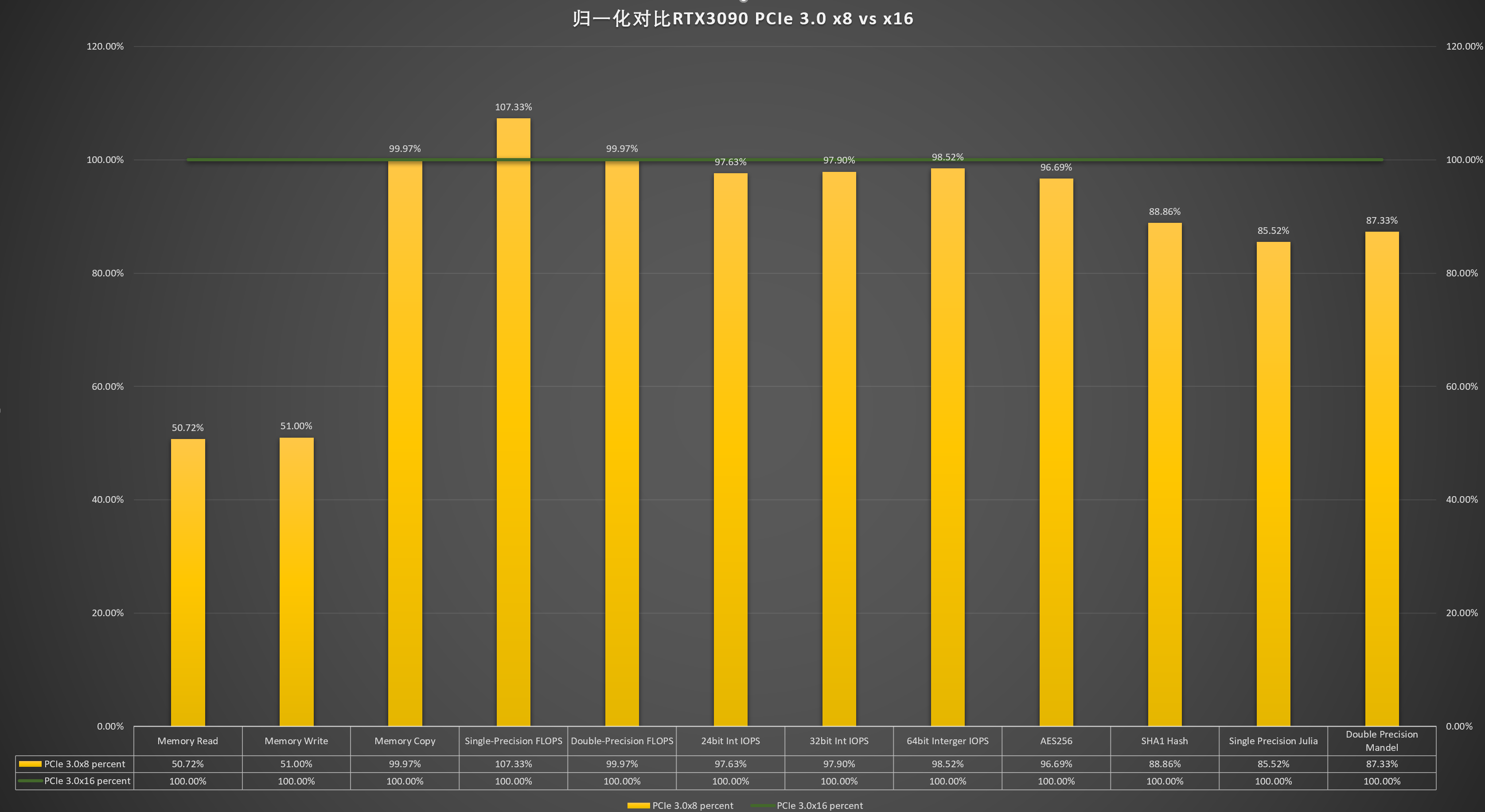
可以看到 Memory Read/Write 确实翻倍了,这个不服不行。我也曾用类似的方法测试过雷电 3 显卡坞的吞吐水平,局限也就在这里。那如果你问我为啥不测测雷电 3 显卡坞 + RTX3090 呢?我只能说大可不必。(实际是我嫌麻烦。)
另外可以看到在单精度、双精度、不同字长的整数做算术运算方面,x8 和 x16 几乎没有区别,当然这也与 AIDA64 的测试程序如何编写的有关。或许可以发一个指令给 GPU,让它在一定范围内生成一些数字然后去并行计算,这样指令传送所用的带宽就很小,不同 lanes 的差异不明显。
最后,在 AES256 分组密码、SHA1 哈希、Julia 的单精度科学计算、Mandel 双精度计算等需要大规模 CPU 参与的测试里,x16 的优势就很明显了。写过 CUDA 程序的同学应该对此很清楚,哪些变量需要显式传递给 GPU 都需要在 C++ 代码里指明,然后交给 CUDA 的编译器去做优化。如果 CPU 和 GPU 之间需要频繁传递大数组,那么 GPU-CPU 的带宽将成为计算的一大瓶颈。所以现在 NVIDIA 正在用自己牛逼的 vSwitch 技术取代 PCIe 做通信,原因就在于 PCIe 限制了 GPU 性能。
那么打游戏呢?老湿基并不喜欢打游戏,所以也没什么可以测试的。不过还是那句话,好不好得看代码怎么写。
M1 Max 牛就牛在内存这一块做的比较好。另外,统一内存指的是物理上通信代价差不多,并不是仅仅指内存、显存的进程虚地址空间统一编码。统一地址空间这件事在 x86 上早就有了。
OK,本期视频专栏就到这里了。老湿马上就晋级 LV6!