一个猜谜语程序的逆向之旅
坑边闲话:猜谜语的游戏想必大家都玩过,所谓的程序谜语,其实并不是考验一个人智力、脑筋急转弯能力的游戏,而是锻炼逆向、动态调试的小 trick. 今天让我们一起感受一下 IDA Pro 7.0 逆向的魅力。
题目来自课后作业,需要的二进制程序在这儿下载。单击下载。
1. 题目描述·
这个程序在 Windows 下编译、运行。
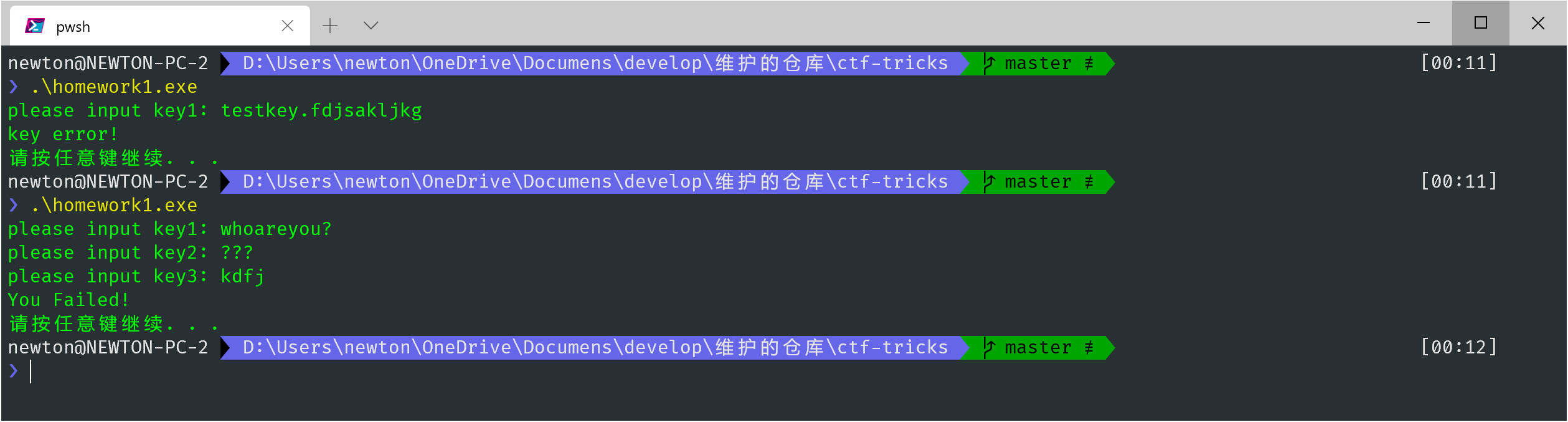
很多同学可能想,这么简单的代码,我逆向进去看看系统里面的字符串不就可以了吗? 然而事情没有这么简单。
2. 逆向·
2.1 恢复 key1·
其实这个题目用动态分析是很难分析的,用静态分析还好一点。动态分析之所以难,是因为里面的所有数据都是临时生成的,添加断点非常困难。
(记住,在 IDA Pro 逆向的时候,分析逆向出来的代码是很困难的,特别是含有相当多业务逻辑的代码。)
逆向之后,我们发现有这么一段代码很有趣:
1 | v3 = malloc(0xBu); |
上面的代码片段中,v3 是一段堆内存的首地址,而 v4 是 v3 的 maintainer,v4 会一直看着这块地址,然后任由 v3 折腾。
再看 v5 = (char *)(&unk_40FA58 - (_UNKNOWN *)v3); 这一句,其中 &unk_40FA58 是一段 rdata 区域的地址,它对应的二进制值为:
1 | .rdata:0040FA58 unk_40FA58 db 78h ; x ; DATA XREF: _main+27↑o |
v5 是这块数据区与刚申请的堆区之间的 offset,而第一个 do-wile 循环里,又利用了这个 offset,将 rdata 中的数据减去 1 之后写入了堆区域。这段代码非常诡异,你要写入就直接写入吧,干嘛还要多此一举,计算 offset 干嘛?两端内存的地址你都有,直接拷贝不好吗?事实并非如此,这正是该程序的诡异之处,它就是想迷惑你,不让你猜测出它的行为。
之后,又申请了 12 个字节的堆内存,然后进行了一系列莫名其妙的操作,真让人摸不着头脑。
1 | printf("please input key1: "); |
上面最后一行代码,被比较的 v7 和 v12 都不是我们直接能得到的数据,所以有理由相信 strcmp 函数的比较对象,都是经过加密的,所以这也印证了我开始的话,直接动态调试是不好分析业务逻辑的。但是经过分析上述代码,我们发现从 rdata 取出的字符和输入的字符,都经过了类似的操作,如
1 | v11 = v8 * v8 + v7[v8 + v9] * v7[v8 + v9]; |
根据对称性,现在无需担心加密过程,我们只需要让输入和 rdata 的那 11 个字符逐字节减 1 一样就可以了。
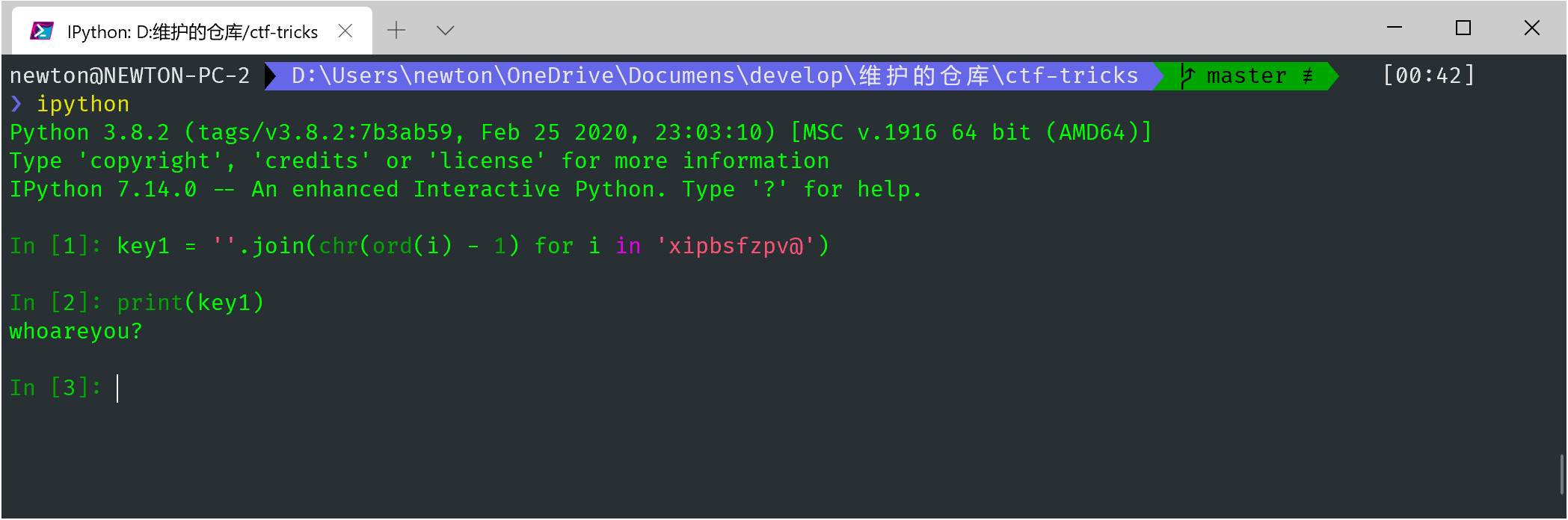
2.2 恢复 key2·
1 | if ( !strcmp(v7, v12) ) |
这个地方就很迷了,系统竟然真的调用了 Dll2.dll 这个动态链接库。其实 .dll 也是可执行程序,全名是 Dynamic Link Library,是一种动态链接的库,而不是简单的静态库,有关动态库和静态库的区别,我们放到后面的文章里讲述,如果有着急的读者,可以参阅《深入理解计算机系统》的第二部分。
话说回来,既然是可执行程序,必然是有结构的,但是很遗憾,这个 Dll2.dll 竟然无法逆向,用 IDA Pro 打开之后,全是二进制码字,IDA Pro 无法解析其结构。
但是我们看到这个返回值为空的函数 sub_401050,它是在判断 Dll2.dll 被成功打开后执行的一套程式,
1 | void __usercall sub_401050(FILE *a1@<ebx>, FILE *a2@<edi>) |
可以发现,这段代码非常简单,就是把两一个传入的文件描述符作为源,另一个文件描述符作为目的地,然后执行一次简单的拷贝:**把 src 里面的数据逐字节减去 1,然后写入 dest 文件。**而且注意,这个目的地文件的命名后缀也是 .dll,这不禁让我联想到,之前的 .dll 打不开,这儿又通过这种蹩脚的方式创建了一个临时文件,会不会这个临时文件才是真正的 .dll 呢?
果不其然,在执行程序过程中暂停,让 DllU.dll 呈现在磁盘上,然后我们偷偷拷贝出来,执行逆向。这样就逆向成功了,原来人家为了防止你逆向动态链接库,耍了这样一个小把戏!
这样回顾 key2 和 key3 就舒服多了。
1 | v19 = GetProcAddress(v17, "?decode@@YAPADPADH@Z"); |
但是上面这一句就有点难以理解了,Windows 编程新手可能从来没见过。其实这是一个很简单的东西。我们通过上文可以知道,v17 = LoadLibraryA("DllU.dll"),可以把 v17 看成一个文件描述符,只是它代表一个动态链接库。这时候,我们给这个动态链接库发送了一个诡异的字符串:?decode@@YAPADPADH@Z. 这个字符串就是 main 函数向动态链接库发送的查询请求,该字符串概念丰富,你单纯地把它理解成一个整体是不行的,必须按照一定的结构去理解。
这个 ?decode@@YAPADPADH@Z 学名叫做调用约定,你可以把它简单理解为一种二进制级别的协议。这个协议的报文,头部以一个 ? 开始,表示可以开始译码了。
- 以“?”标识函数名的开始,后跟函数名。
- 如果是
__cdecall调用约定,函数名后面接@@YA标识参数表的开始; - 如果是
__stdcall调用约定,函数名后面接@@YG标识参数表的开始; - 如果是
__fastcall调用约定,函数名后面接@@YI标识参数表的开始。 - 后面再跟参数表,参数表以代号表示,参数表的第一项为该函数的返回值类型,其后依次为参数的数据类型,指针标识在其所指数据类型前;
X–voidD–charE–unsigned charF–shortH–intI–unsigned intJ–longK–unsigned longM–floatN–double_N–boolPA–指针
- 参数表后以
@Z标识整个名字的结束,如果该函数无参数,则以Z标识结束。
只要你把这个调用约定给一个 .dll 链接库,那就可以唤出其中编译好的程序。根据这个原理,?decode@@YAPADPADH@Z 代表一个 dll 中的函数,原型为:char __cdecl * decode(char *tem1 , int tem2)

1 | v18 = LoadLibraryA("DllU.dll"); |
逆向出来的代码不太好读,上面这段代码经过我稍微修改,不影响上下文逻辑关系。现在可以总结调用过程如下:
LoadLibrary函数打开磁盘上的动态链接库文件GetProcAddress函数将函数选择子和动态链接库文件描述符结合起来,取出函数- 被取出的函数经过添加各种修饰符,进行包装,得到能在本程序中运行的函数
- 直接调用函数
经过逆向动态链接库,找到了 decode 函数的细节。
1 | char *__cdecl decode(char *a1, int a2) |
上面这个 decode 函数虽然很乱,但也可以看出,它通过分析第二个参数,展示了不同的译码行为。
- 当参数 2 为
1时,decode 方式为BYTE \^ 0x77(可以理解为逐字节解码,类似分组密码) - 当参数 2 为
2时,decode 方式为(((BYTE & 0xF0) >> 4) & 0xF) + 16 * (BYTE & 0xF)
那就很简单了,让我们直接从 rdata 取出参数 1,直接手写一个 Python 脚本,自己进行解密,得到 key2 和 key3 不就行了吗!此处原理类似 key1.
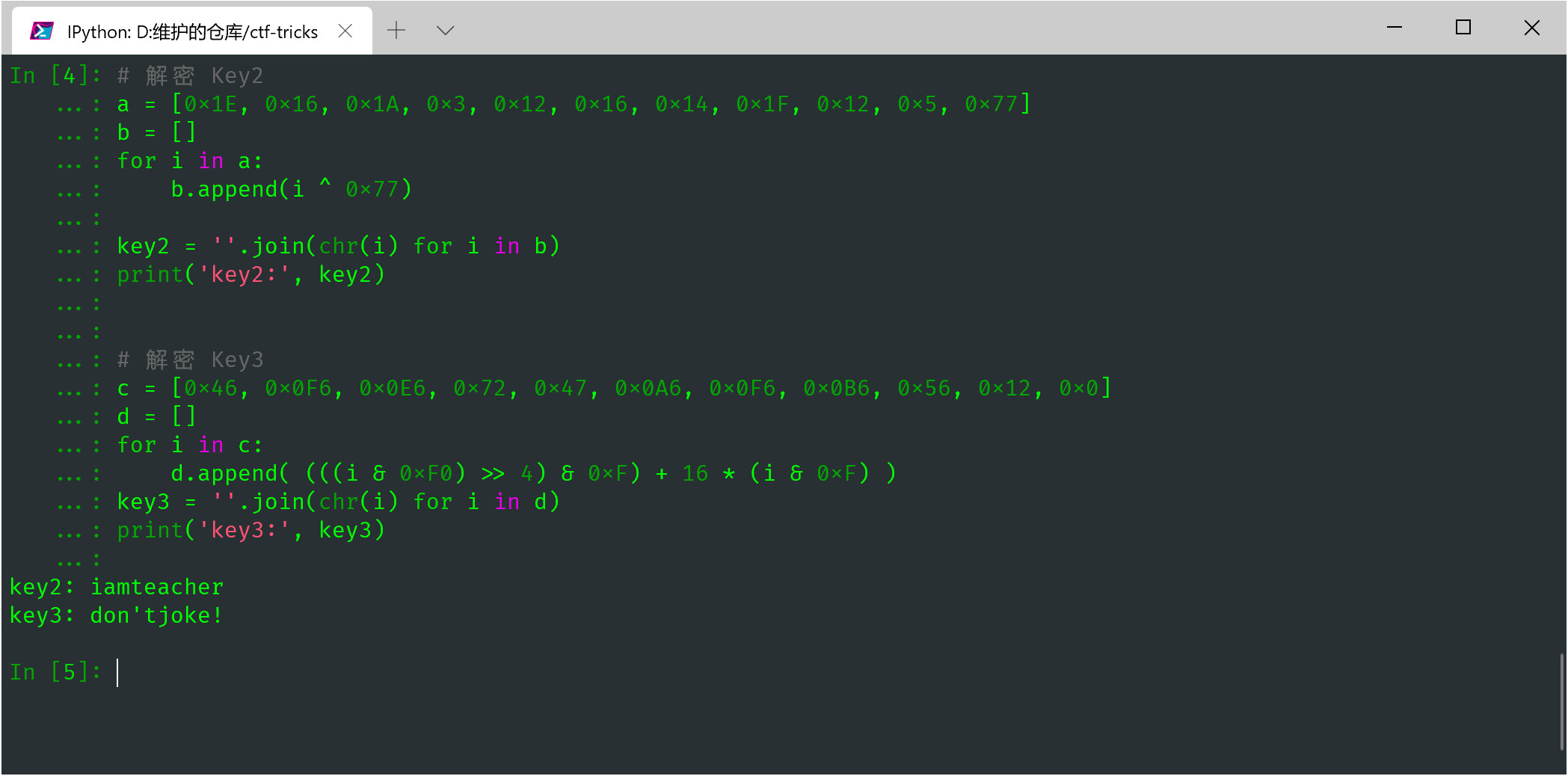
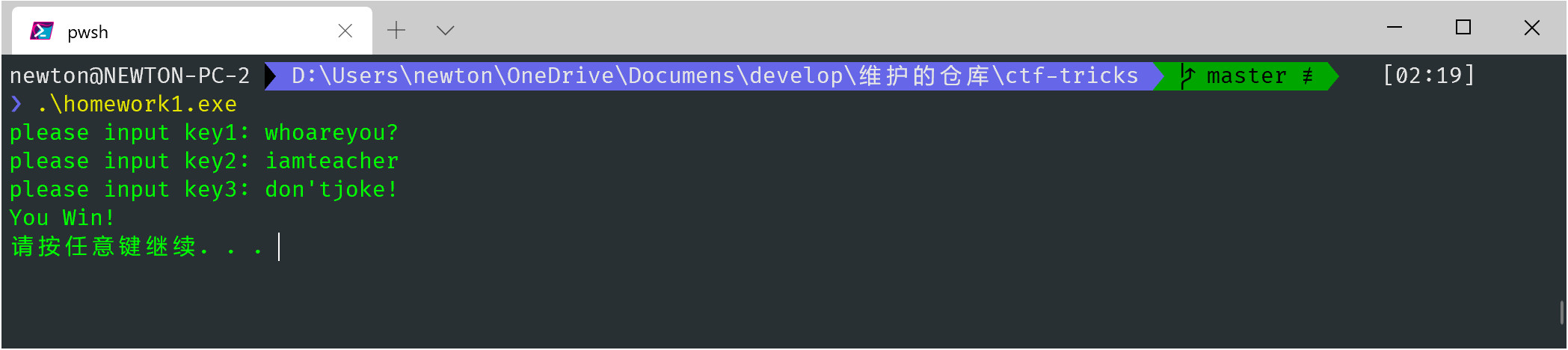
当然,如果函数很复杂,一时半会写不出来,就需要利用 .dll 进行运行,好在这里只是两行代码,非常简单。
总结·
可以发现,程序为了防止你逆向,可谓是煞费苦心,分别通过以下方式:
- 明文都经过加密后存在了 PE 可执行格式文件的数据区中,直接逆向什么都得不到
- 重要的 dll 没有直接暴露出来,而是经过了一个中间解密,得到临时 dll,用完了之后会把真 dll 删掉,防止被发现
但是这种方式也是很有问题的,密码原理告诉我们,凡是遵从单一程式而没有密钥输入的密码系统,一定是不安全的。所以,这个小程序被我们恢复出来了。反过来想想,如果想彻底让别人无法猜测,首先要做的就是不能让敌人拿到可执行程序,否则别人总能翻来覆去研究,最终破解。
安全之路,必然是需要以来数学安全性的,看起来很乱、几乎无法恢复的背后,原理竟然这么幼稚。
Cover 劳动节第四篇文章