个人 PDF 知识仓库构建 p3:PDF 电子书的精细化处理
坑边闲话:第 1 讲和第 2 讲中,我描述了为何要建立一个电子档 PDF 书籍的仓库。但是万事万物都不是拿来就好,必须经过一番细致的处理才能为我所用,否则一味追求“大而全”,将会沉溺于虚无之中。慢下来,审视自己的需求,是第一步。
我曾见过太多的人,把收藏书籍、收藏微信精品公众号推送、收藏手机拍摄的上课的 PPT 等作为一种学习,或许他们真的想过,自己会在未来的某一天,能找一段大块的连续时间,把这些旧日的收藏好好审视一番,然而大多数人都没有这个机会。我们不可避免陷入一种进退两难的境地:究竟是收集一个就立即处理一个,还是等收集到一批之后集中处理?一次处理一个,难免效率很低,浪费大量时间在 IO 上,类似于设计交换机时,CPU 的 PPS 数目一定时,包越大越容易达到交换的吞吐性能,反之,小 packet 会严重浪费吞吐量。然而,等累积到一定量再处理,则很难把握这个累积量的大小。
所以在看本文之前,一定要在心中默念下面几句话,否则极易走火入魔!
- 我搜集 PDF 是为了满足自己的学习和科研,而不是为了满足自己那个潜在的追求满足感的心。过于简单地被满足,就很容易使我变得低俗和不思进取。
- 如无必要,尽可能不要搜集很多 PDF 电子档。以下三个方面是可以做的:
- 为了了解某一个领域,如计算机网络,可以搜。比如把 Computer Networks: A Systems Approach 的推荐列表、书后参考文献的电子档都找出来是可以的;
- 为适应某个学校课程的需要,可以把老师给的推荐列表书目都找一遍,以防以后需要时没有参考;
- 学完了某门课程,可以把该领域著名的专著找出来,以供日后翻阅或者给别人讲解。
- 我所搜集到的 PDF 电子档必须是完整的、未经篡改的、高质量的,一定要本着宁缺毋滥的原则去搜集,同时我要对我所有的 PDF 电子档进行良好的集中管理。
当你认真读了上述原则性纲领之后,就可以继续本文的阅读了,否则直接看操作,可能对你有害。切记!
1. 方法概述·
现在我们要假设,你已经获得了某份扫描质量还不错的 PDF,那么你该如何处理呢?
- 扫描清楚、完整吗?如果是,就继续,否则直接抛弃这份 PDF,goto end.(宁缺毋滥)
- 这份 PDF 有标准的书签吗?如果 No,就继续,否则 jmp to 步骤 4
- call 生成 PDF 标准电子书签的方法 (参考第 3 节)
- 这份扫描版 PDF 内嵌了文本层吗?如果 No,就继续;否则就 jmp to end
- call PDF OCR 方法
- end
从上述“算法”中我们可以看到,其实整理 PDF 主要集中在两大方法上:书签制作与 OCR 处理。下面将详细描述这两大方法。
2. OCR 处理·
如果你从知网(cnki.net)下载过学位论文,你应该知道,这些学位论文基本都是扫描的,但是神奇的是它们竟然都可以像矢量版(Word/LaTeX 直接输入版)那样被选择、复制,这可是太神奇了!其实这也没什么好值得惊讶,无非是在图像层上方,覆盖了一层透明的文本层,而且文本与图像中的字体、位置一致罢了。
支撑这个功能的是 OCR 算法(光学字符识别算法),即把图片中的文字通过程序,转换为对应的文字。学习图像处理的同学应该发现了,很多机器学习教材就是以简单的手写阿拉伯数字 OCR 作为入门练习的!
将书本通过扫描仪制作为 PDF,就是扫描过程。这种过程得到的 PDF 本质上就是图片,该过程也类似于手机拍照,只不过扫描仪会对图片亮度、对比度进行一些预处理,但是不可否认,你得到的 PDF 就是一堆照片。对这种图片 PDF 进行 OCR 的程序有不少,但是本着宁缺毋滥的原则,这里仅推荐一款最强的:Abbyy FineReader(abbyy.com)。其他软件,在多线程调用、识别精准度上都有各种问题,这里就不解释了。
再说一遍:Abbyy FineReader.
该软件在 Windows 上表现良好,同时该软件是付费软件,标准版含税价格 1300 RMB 多,实在囊中羞涩,也可以到胡萝卜周的博客(carrotChou.blog)搜索破解版。但还是那句老话,有钱记得支持正版。如支持正版,请到官方网站购买,abbyyChina.com 与官方网站 abbyy.com 是不同的网站,前者是授权给思杰马克丁这家流氓公司之后,专为中国用户设置的网站,从这里购买的序列号可能是有问题的,特此提醒。
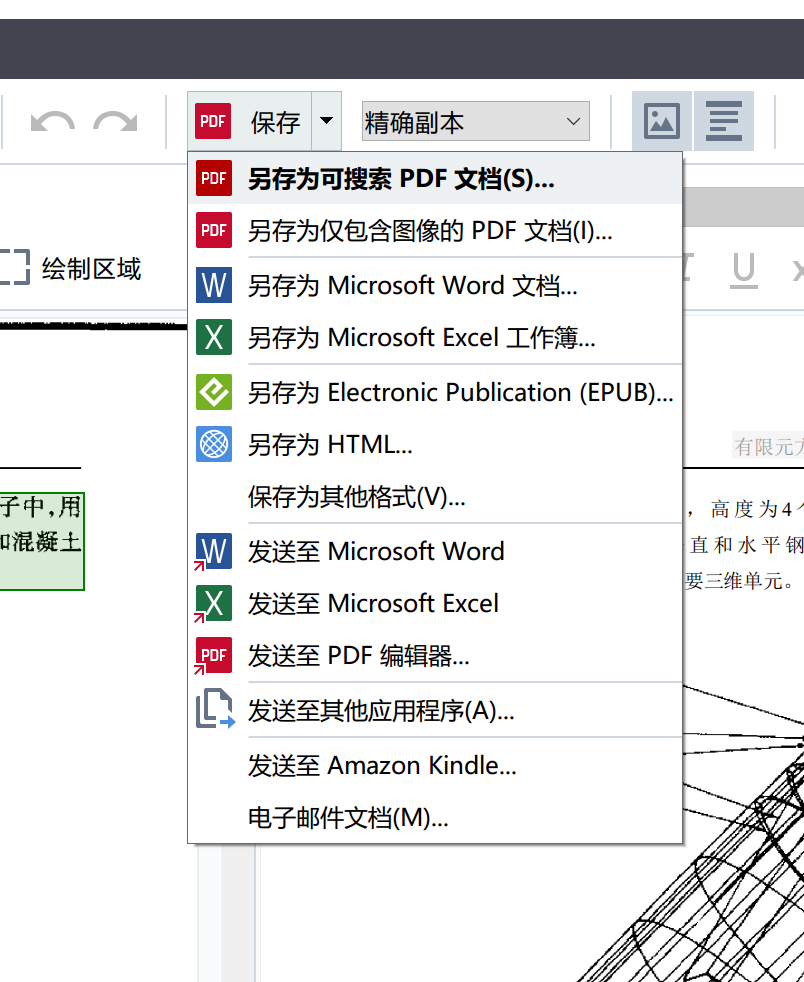
打开 Abbyy FineReader 15 OCR 编辑器,然后在工具–>选项里,进行如下设置:
搞定了这些 Configure,就可以放心大胆地把扫描版 PDF 进行处理了。直接将 PDF 拖拽到 Abbyy FineReader 15 OCR 编辑器中,本质上是将 PDF 复制了一份,所以原 PDF 不会被修改,这也类似于编程中的 Deep Copy. 等 PDF OCR 完成之后,Abbyy 软件会以不同的颜色标记置信度比较低的区域。
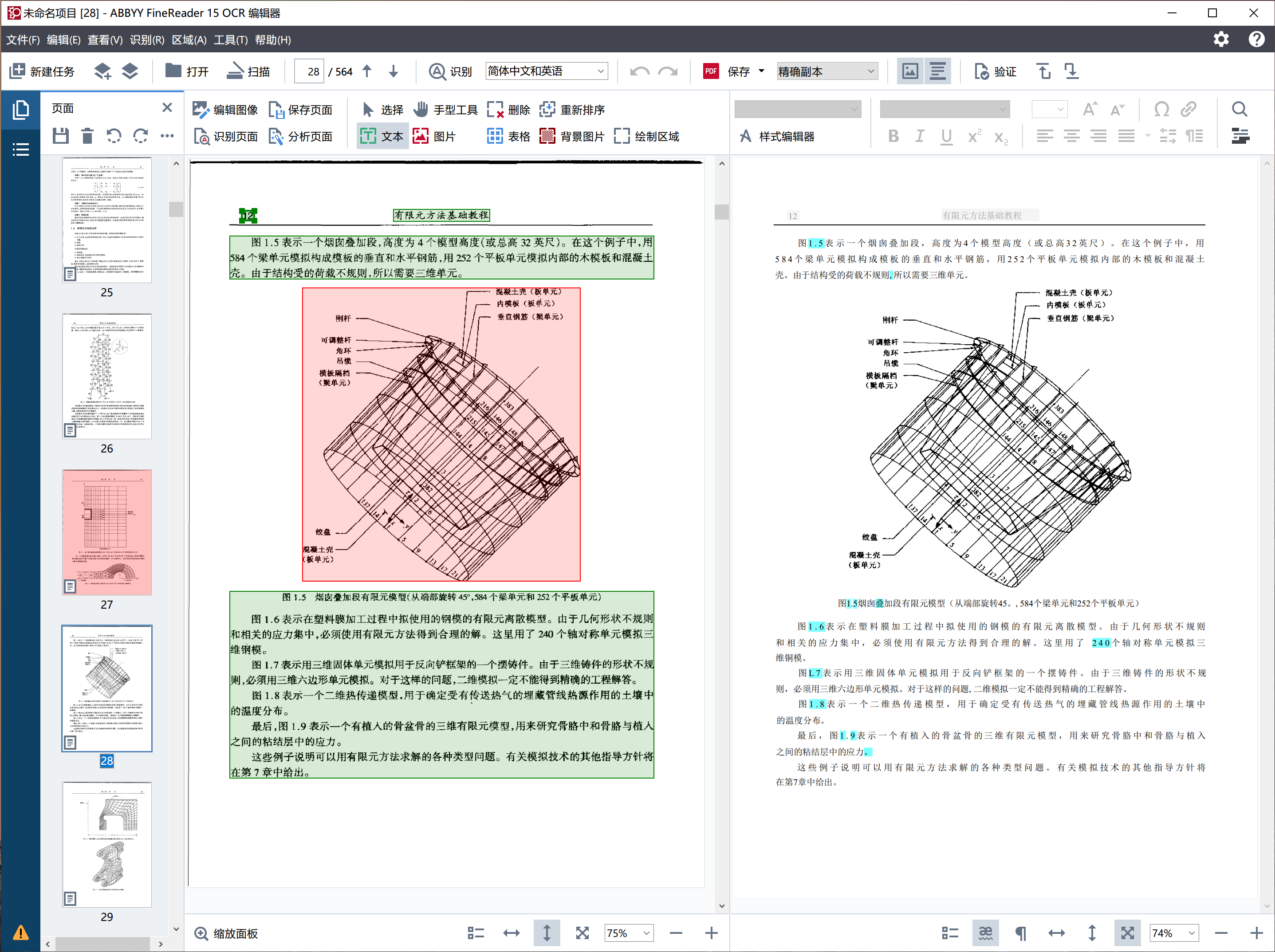
Abbyy FineReader 的识别是按照 预处理 -> 划分文本区域、图像区域 -> 按区域类型进行 OCR 等流程进行的,所以这种按部就班的流程特别容易并行流水线化(Pipeline)实现,所以 Abbyy 的 CPU 利用率很高。
OCR 完之后,就可以保存。
搞定了这些,我们就得到了一份带有文本层的 PDF 扫描件。但是这仅仅是完成了初步处理。接下来要完成书签制作与页面显示设置。
3. 书签制作·
如勾选了自动生成书签,那么会得到一个带有较为杂乱书签的 PDF. 正如扫描本身就是一个提取部分信息的过程一样,自动化的 OCR 并不完美,它也不能恢复所有信息。自动生成的书签往往很丑陋,乱七八糟是常态。我个人一般把 Abbyy 的自动生成书签功能关闭。
书签是很有用的,通过书签我们可以快速跳转浏览,没有书签的电子档读起来相当费劲。制作书签需要 4 个工具,后缀 .exe 是为了告诉大家,这些软件是 Windows 专属,Mac 暂时没有:
FreePic2Pdf.exe,这是一个可以从 PDF 中提取书签、挂书签的软件;PdgCntEditor.exe,这是一个直接打开 PDF 文件并编辑其书签的编辑器,功能非常强大;- 支持正则表达式的文本编辑器,如
Visual Studio Code; Adobe Acrobat Pro DC,目前看来此软件无法替代,而且是收费版的,囊中羞涩的朋友再去胡萝卜周的博客搜索一番吧。
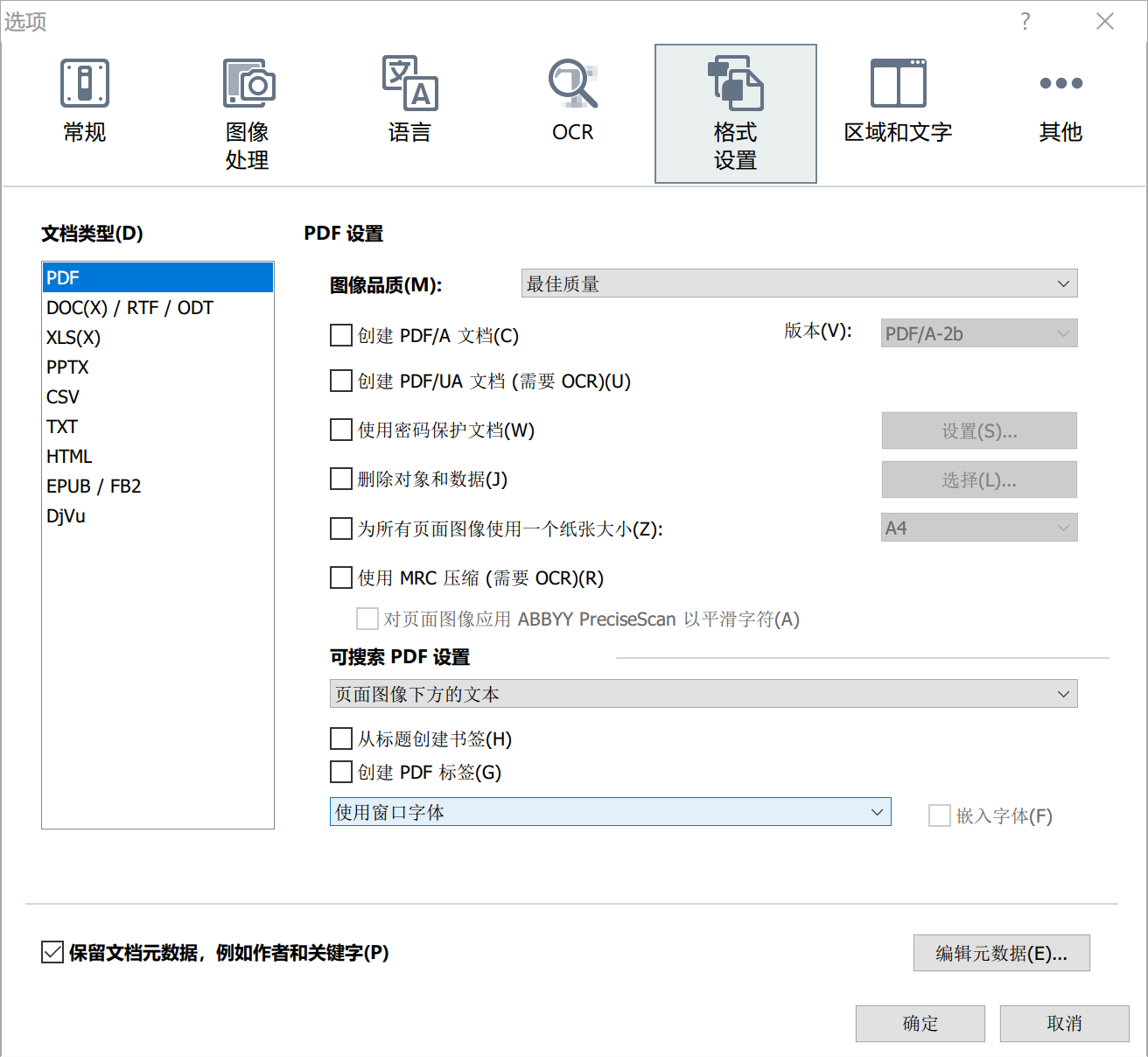
如仅需要对书签进行部分变更,那么 FreePic2Pdf 是个很有用的软件,你可以用它将书签提取出来,然后用文本编辑器编辑一下,再保存回去。如 PDF 本身的书签没有任何价值,那么只需要 PdgCntEditor 即可:制作一份好的书签,用 PdgCntEditor 打开目标 PDF,然后把书签文本粘贴进去。
以上两个软件的书签对象都是纯文本。我们的 PDF 中自带的书签也无非是这样:书签之间呈现有序的树状的层级关系,每个书签对应一个 PDF 页面或者页面中的某个位置。所以只需要在书签文本中标注好层级结构以及每个书签对应的页码即可。在文件结构中,层级关系用缩进表示,这类似于 Python 中的 indent 机制,而缩进一律采用 TAB 制表符,不可用空格代替。每条书签由 4 部分组成:
- 开头的零个或多个制表符(表示层级关系)
- 书签文本(书签的显示字样)
- 一个制表符(起分隔作用)
- 页码(整数)
假如原 PDF 中不含书签,那该如何是好?这时候只能退而求其次,要么去出版方、豆瓣找找目录,要么就复制 OCR 后的目录页文字,然后手动修改为软件可识别的结构。这是整个过程中最费功夫的一关,但是必须要做。掌握良好的正则表达式查询技能,可以大大降低该过程的难度。如有机会,后面会单独出一个教程或文章,教大家如何用几个正则表达式和列操作快速构建标签页文件。掌握了正则表达式的基本技能之后,操作这个步骤,对于一般的书可能只需要 5 分钟左右。
值得说明,由于 PDF 中的页面并不是按照连续的 1-N 标记,而是每个页面都有自己的标签。这个概念其实很好理解,我们认为的第一页到最后一页并不是软件认为的,他们只会识别页面标签。

本文致力于把逻辑和部分容易忽略的细节告诉读者,非常详细的步骤和软件的具体操作,还请自行研究。如正确掌握了思维逻辑,那么掌握这些软件都不是难事,水到,渠成。
小结:逻辑页面与物理页面需要用页面标签进行沟通,取书签、挂书签需要用那两款迷你免费软件操作,没有书签的 PDF 需要用若干种方法得到书签信息,可从网上找目录,也可以自己从 OCR 的目录页面中复制出来然后处理。
4. 总结·
没有什么学习是看看教程就会了的,一定要自我钻研,否则只能是吃别人嚼过的东西,恶心得很。看完文章,下载一下软件,然后把帮助文档好好读一遍,就大体把基础技能掌握了。这是个自我提高的过程,不会很舒服的。接下来我们将迈入 PDF 文件管理的新篇章。





